



ETL Nedir, ELT Nedir? Power BI + SQL + Data Warehouse ile Doğru Mimariyi Seçme Rehberi
İş zekâsı projelerinde en sık yapılan hatalardan biri, daha en başta yanlış soruyu sormaktır. “ETL mi yapalım ELT mi?” sorusu tek başına eksik kalır. Asıl soru şudur:
“Bizim veri hacmimiz, kaynak sistemlerimiz, ekip yetkinliğimiz, raporlama ihtiyacımız ve güvenlik kısıtlarımız için en sürdürülebilir veri akışı hangisi?”
Çünkü ETL/ELT seçimi; sadece teknik bir tercih değil, doğrudan:
- raporların hızını,
- veri kalitesini,
- operasyon maliyetini,
- geliştirme hızını,
- ve uzun vadede bakım yükünü belirler.
Bu rehberde ETL ve ELT’yi netleştireceğiz; ardından Power BI + SQL + Data Warehouse dünyasında “hangi senaryoda hangisi” sorusuna pratik bir karar çerçevesi vereceğiz.
ETL Nedir?
ETL = Extract (Çek) → Transform (Dönüştür) → Load (Yükle)
Yani veriyi kaynaktan çekersiniz, genellikle bir ETL aracı/servisi üzerinde dönüştürürsünüz, sonra hedef sisteme (Data Warehouse gibi) yüklersiniz.
ETL’nin temel özellikleri
- Dönüşümler yüklemeden önce yapılır
- Hedef veri ambarına “hazır, temiz, kuralı uygulanmış” veri gider
- Veri kalitesi ve kontrol noktaları ETL katmanında toplanır
ETL’nin “klasik” kullanım alanı
- Kurumsal Data Warehouse (DWH) yapıları
- On-prem SQL Server + SSIS benzeri senaryolar
- Sıkı kurallı, denetlenebilir raporlama sistemleri
ELT Nedir?
ELT = Extract (Çek) → Load (Yükle) → Transform (Dönüştür)
Bu yaklaşımda veriyi önce hedef platforma (DWH/Lakehouse) ham veya yarı-ham şekilde yüklersiniz. Dönüşümleri ise hedefin kendi işlem gücüyle (çoğu zaman SQL ile) gerçekleştirirsiniz.
ELT’nin temel özellikleri
- Dönüşümler yüklemeden sonra yapılır
- Hedef platform güçlü işlem kapasitesi sunar (warehouse/lakehouse)
- Ham veriyi saklamak kolaylaşır (yeniden işleme, versiyonlama)
ELT’nin “modern” kullanım alanı
- Bulut tabanlı lakehouse/warehouse mimarileri
- Büyük veri, yarı-yapısal veri (JSON/log vb.)
- Dönüşüm kurallarının hızlı değiştiği ürün/analitik ekipleri
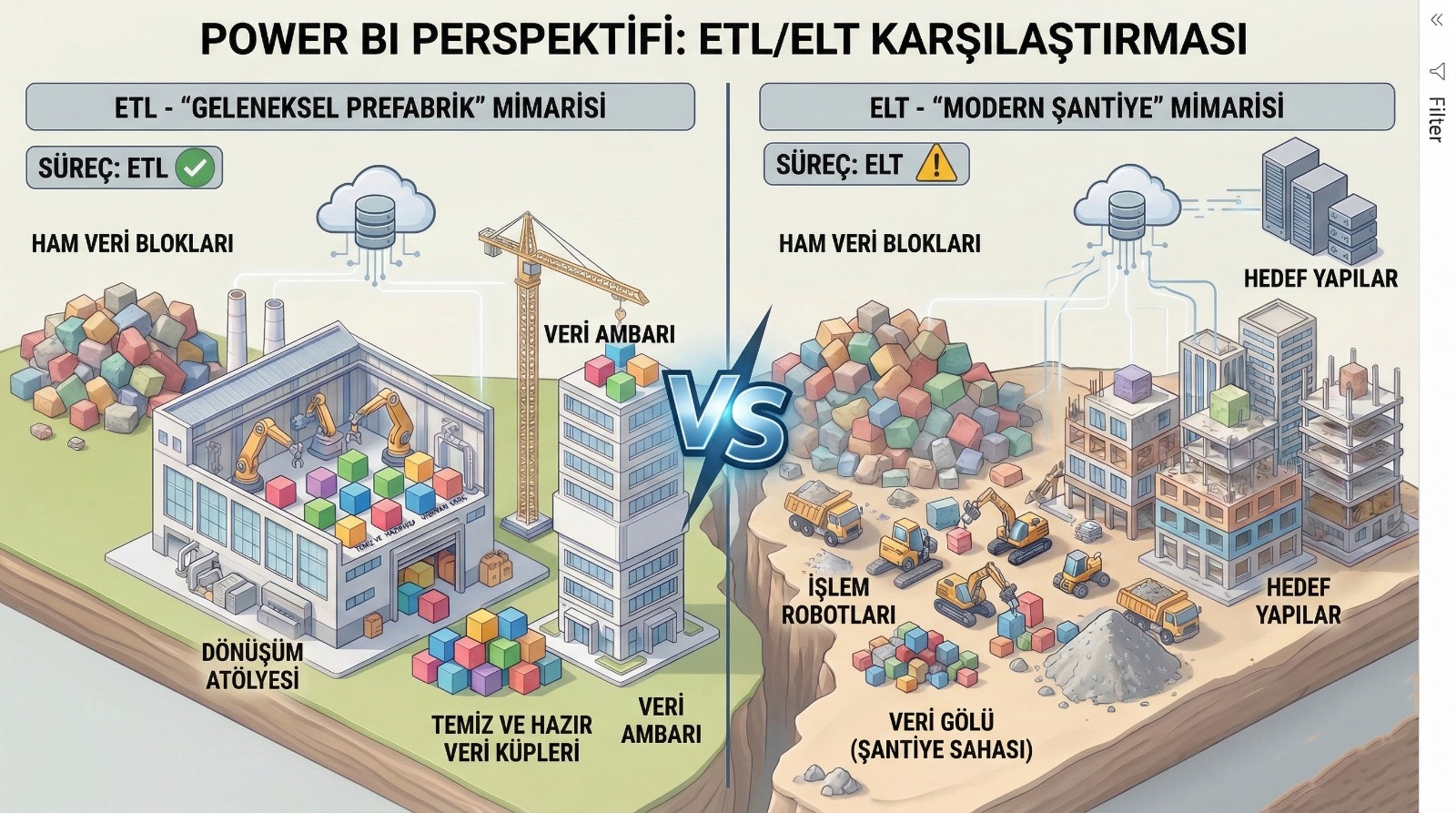
ETL vs ELT: Kısa Karşılaştırma
Aşağıdaki tablo “tek bakışta” farkı oturtur:
| Kriter | ETL | ELT |
| Dönüşüm nerede yapılır? | ETL katmanında | Hedef platformda (DWH/Lakehouse) |
| Hedefe giden veri | Temizlenmiş, kuralı uygulanmış | Ham / yarı-ham + sonra kural |
| Esneklik | Orta | Yüksek |
| Ham veriyi saklama | Genelde sınırlı/opsiyonel | Genelde standart pratik |
| Performans yaklaşımı | ETL katmanı optimize edilir | Warehouse/Lakehouse compute kullanılır |
| Yönetişim (governance) | ETL’de merkezi kontrol | Model katmanlarında disiplin gerekir |
| Hangi ekip daha rahat? | ETL/BI ağırlıklı ekipler | Analytics engineering / SQL ağırlıklı ekipler |
Kısa özet:
ETL daha “kontrollü ve klasik”; ELT daha “esnek ve modern” bir yaklaşımdır. Ama “modern = her zaman doğru” değildir.
Microsoft İş Zekâsı Ekosisteminde ETL ve ELT Nasıl Konumlanır?
Power BI + SQL + DWH dediğimizde pratikte iki ana mimari dünyası görürüz:
1) SQL Server tabanlı klasik DWH (ETL ağırlıklı)
- Kaynaklar: ERP/CRM/operasyon DB’leri
- ETL: SSIS benzeri akışlar / planlı job’lar
- Hedef: SQL Server Data Warehouse (boyut-fakt)
- Sunum: Power BI semantic model / dataset
Bu dünyada ETL doğal oturur: DWH’ye temiz veri yüklersiniz, Power BI modeli hızlı olur.
2) Lakehouse/Warehouse tabanlı modern analitik (ELT ağırlıklı)
- Kaynaklar: DB + API + dosyalar + loglar
- Önce yükle: ham veri “landing/staging” alanına
- Sonra dönüştür: SQL tabanlı dönüşümlerle “gold” katman
- Sunum: Power BI (Import/DirectQuery/Composite) + semantic model
Bu dünyada ELT, “ham veriyi sakla → ihtiyaca göre dönüştür” mantığıyla güçlüdür.
Power BI Perspektifi: ETL/ELT Seçimi Rapor Performansını Nasıl Etkiler?
Power BI performansının temeli genelde şunlara dayanır:
- Modelleme (star schema)
- Veri hacmi ve granülerlik
- Yenileme (refresh) stratejisi
- Import/DirectQuery seçimi
ETL/ELT seçimi bu alanlara doğrudan dokunur:
ETL tarafında avantaj
- DWH katmanı “rapora hazır” olduğu için Power BI modeli daha hızlı kurulur
- Boyut-fakt yapısı netleşir
- Veri kalitesi kuralları önce uygulanır
ELT tarafında avantaj
- Ham veriden başlayıp ihtiyaç oldukça model üretmek kolaydır
- Yeni rapor ihtiyacında “yeniden ETL yazma” yükü azalabilir
- Dönüşümler SQL ile yönetilebildiği için iterasyon hızlıdır
Pratik gerçek:
Power BI tarafında en kritik hedef genelde star schema’dır. ETL de ELT de bu hedefe hizmet edebilir. Önemli olan dönüşümleri nereye koyduğunuzdan çok, sonuçta Power BI’ın beslendiği “gold” katmanın düzgün tasarlanmasıdır.
Hangi Senaryoda ETL Daha Doğru Tercih Olur?
Aşağıdaki durumlar ETL’yi avantajlı yapar:
1) On-prem ve kaynak sistem hassassa
Kaynak sistemleri yormadan, kontrollü yükleme pencereleriyle veri taşımak gerekiyorsa ETL daha düzenlidir.
2) Veri kalitesi ve denetim (audit) kritikse
Finans, muhasebe, regülasyon gibi alanlarda:
- kurallar net,
- değişiklikler kontrollü,
- audit izleri gerekli ise ETL yaklaşımı daha güvenli olur.
3) Dönüşümler çok kompleks ve “pipeline” odaklıysa
Bazı dönüşümler (özellikle çok adımlı iş kuralları) ETL akışında daha yönetilebilir olabilir.
4) Ekip “BI/ETL kültürü” ile güçlü ise
ETL araçlarına hakim ekipler ETL ile daha hızlı ve daha az riskle ilerler.
Hangi Senaryoda ELT Daha Doğru Tercih Olur?
ELT’yi güçlü yapan tipik durumlar:
1) Veri çeşitliliği yüksekse (DB + API + dosya + log)
Ham veriyi önce toplayıp sonra ihtiyaç oldukça dönüştürmek daha esnektir.
2) Dönüşüm kuralları sık değişiyorsa
Ürün analitiği, growth, deneyler, hızlı iterasyon gerektiren yapılarda ELT yaklaşımı daha çeviktir.
3) Hedef platform güçlü işlem kapasitesi sunuyorsa
Warehouse/lakehouse tarafında ölçeklenebilir compute varsa dönüşümü orada yapmak mantıklıdır.
4) “Ham veri” saklamak stratejikse
Geriye dönük yeniden işleme, yeni KPI türetme, veri bilimi/ML ihtiyaçları varsa ham verinin tutulması büyük avantaj sağlar.
Hibrit Yaklaşım: Gerçekte En Çok Kullanılan Model
Sahada çoğu kurum “tam ETL” veya “tam ELT” değildir. En sürdürülebilir yapı genelde hibrittir:
Katmanlı mimari (Bronze / Silver / Gold)
- Bronze (Raw/Landing): Ham veri
- Silver (Clean/Conformed): Temizlenmiş, standardize edilmiş veri
- Gold (Serving): Raporlamaya hazır boyut-fakt, özet tablolar
Bu yaklaşımın güzelliği şudur:
- Ham veri kaybolmaz
- Dönüşümler katman katman yönetilir
- Power BI’a giden “gold” katman performans odaklı tasarlanır
Karar Çerçevesi: ETL mi ELT mi? (7 Soru ile Netleştirin)
Aşağıdaki soruları cevaplayın. “Evet” ağırlığı hangi tarafa kayıyorsa seçim de oraya yaklaşır.
- Kaynak sistem çok hassas mı, ağır sorgu kaldıramıyor mu?
→ Evetse ETL eğilimi artar. - Ham veriyi saklamak zorunlu mu / çok değerli mi?
→ Evetse ELT eğilimi artar. - KPI ve iş kuralları sık değişiyor mu?
→ Evetse ELT eğilimi artar. - Regülasyon / audit / veri doğruluğu kritik mi?
→ Evetse ETL eğilimi artar (veya hibritte “silver/gold” çok disiplinli olmalı). - Ekip hangi tarafta daha güçlü?
- ETL aracı ve pipeline disiplini mi? → ETL
- SQL dönüşüm, model katmanı disiplini mi? → ELT
- Veri hacmi ve çeşitliliği ne durumda?
- Çok kaynak, çok format → ELT/hibrit
- Az kaynak, net şema → ETL
- Power BI’da hedef mod ne?
- Import ile performans hedefleniyorsa → “gold” katmanın sağlam olması şart (ETL veya ELT fark etmez)
- DirectQuery ağırlıksa → kaynak/warehouse optimizasyonu kritik (ELT + iyi SQL tasarım öne çıkar)
Örnek Mimari Senaryolar
Senaryo A: Klasik Kurumsal DWH (ETL ağırlıklı)
Akış:
- Operasyon DB (ERP/CRM)
- Staging alanı
- ETL dönüşümleri (iş kuralları + kalite kontrolleri)
- DWH (Star schema: Fact + Dimension)
- Power BI (semantic model + raporlar)
Ne zaman ideal?
Raporlar net, yönetim KPI’ları stabil, veri yönetişimi güçlü isteniyor.
Senaryo B: Lakehouse/Modern Analitik (ELT ağırlıklı)
Akış:
- Kaynaklar (DB + API + dosya + log)
- Raw/Landing (ham)
- Warehouse/Lakehouse üzerinde SQL dönüşümleri
- Gold katman (boyut-fakt + özet)
- Power BI (import/composite)
Ne zaman ideal?
Çok kaynak var, sürekli yeni ihtiyaç geliyor, hızlı iterasyon şart.
Senaryo C: Hibrit (En gerçekçi saha yaklaşımı)
Akış:
- Ham veri landing’de tutulur (EL)
- Temel temizlik/standardizasyon yapılır (Silver)
- Raporlama için star schema + aggregation tablolar üretilir (Gold)
- Power BI gold katmandan beslenir
Ne zaman ideal?
Hem denetim istiyorsun hem esneklik. “İkisini birden” isteyen kurumların çoğu buraya düşer.
En Sık Yapılan Hatalar (Projenin Maliyetini Patlatır)
- “Ham veriyi direkt Power BI’a bağlayalım” (sonra model şişer, performans düşer)
- Her rapor için ayrı dönüşüm kuralı yazmak (tekil KPI’lar çoğalır, tutarsızlık artar)
- Star schema yerine “operasyonel şemayı rapora taşımak”
- Incremental yükleme stratejisi kurmamak (refresh süreleri uzar)
- Veri sözlüğü/KPI tanımlarını yazmadan ilerlemek (aynı KPI farklı hesaplanır)
Başlangıç İçin Pratik Checklist
Başlarken şu adımlarla ilerlemek çoğu projede işleri hızlandırır:
- “Gold katman” hedefini netleştir: Power BI neyi tüketecek?
- Boyut-fakt model taslağını çiz (star schema)
- Ham veriyi saklama ihtiyacını belirle (raw katman gerekli mi?)
- Incremental yükleme stratejisini baştan planla
- KPI sözlüğü hazırla (tanım, filtre, tarih mantığı)
- Power BI modunu belirle (Import/DirectQuery/Composite)
Sonuç: Doğru Seçim “ETL mi ELT mi” Değil, “Hangi Katmanda Ne Yapmalı?”
ETL ve ELT birbirinin düşmanı değil; doğru kurgulanınca birbirini tamamlayan iki yaklaşımdır. Power BI + SQL + Data Warehouse dünyasında sürdürülebilir başarı genelde şuradan gelir:
- Ham veri yönetimi (gerekliyse)
- Katmanlı dönüşüm disiplini (silver/gold)
- Raporlamaya özel, performans odaklı star schema
- Yenileme stratejisi (incremental)
- Tek bir “doğru KPI” kaynağı (governance)
Kısacası: Mimariyi iş ihtiyacına göre kurarsanız, ETL/ELT seçimi zaten “doğru yere” oturur.
Sıradaki Okumalar (İç Link Önerileri)
- Power BI Performans Optimizasyonu: Modelleme, Star Schema, Aggregation ve Hızlandırma Teknikleri
- SSIS ile ETL Tasarımı: Incremental Load, CDC ve Hata Yönetimi (Adım Adım)
- Veri Deposu Nedir? Kimball ile DWH Tasarımı: Fact, Dimension, SCD ve KPI Yönetimi
CTA (İletişim / Hizmet Metni)
Kurumunuz için ETL mi ELT mi daha doğru; bunu en net gösteren şey mevcut tablo hacimleri, kaynak sistem tipi ve Power BI kullanım şeklidir. İsterseniz mevcut yapınızı değerlendirip (1) hedef mimari, (2) katmanlı akış planı, (3) star schema taslağı ve (4) refresh/performans stratejisi içeren uygulanabilir bir yol haritası çıkarabiliriz.


