


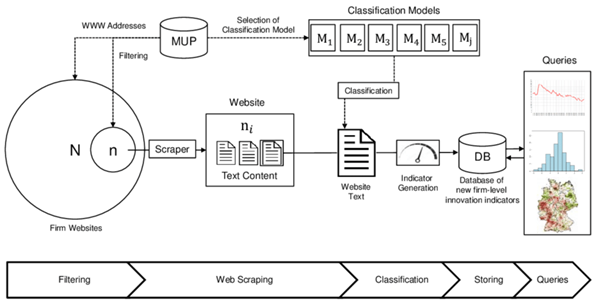
Yazılım çözümlerimizle iş süreçlerinizi optimize edin, özel projelerle müşteri deneyiminizi ve verimliliğinizi artırın. arcayazilim.com
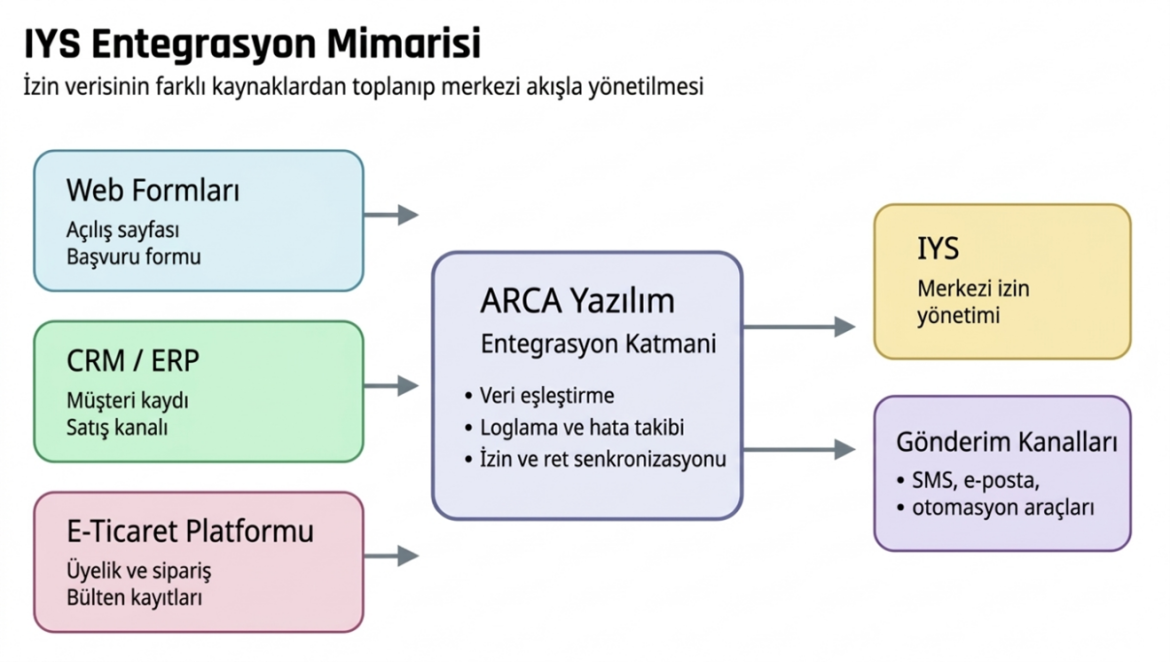
İYS entegrasyonu, ticari elektronik ileti gönderen işletmeler için artık yalnızca teknik bir detay değildir. Doğru kurgulanmış bir süreç; yasal uyumu, müşteri güvenini ve kampanya performansını aynı anda etkiler.
IYS Entegrasyon çözümleri arayan firmalar için temel ihtiyaç genellikle aynıdır: SMS ve e-posta izinlerini tek merkezden yönetmek, ret taleplerini gecikmeden işlemek ve operasyonu hatasız sürdürmek. Bu noktada ARCA Yazılım IYS projeleri için uçtan uca entegrasyon yaklaşımı sunar.
İYS nedir?
İYS, yani İleti Yönetim Sistemi; ticari elektronik ileti izinlerinin merkezi olarak yönetilmesini sağlayan yapıdır. İşletmeler, müşterilerinden aldıkları ileti onaylarını bu sistemle ilişkilendirir ve ret süreçlerini kayıt altına alır.
Özellikle SMS, e-posta ve arama izinleri farklı kanallarda toplanıyorsa, manuel takip hızla sorun yaratır. İYS entegrasyonu ise bu dağınık yapıyı tek akışta birleştirir.
İYS entegrasyonu neden önemlidir?
İleti Yönetim Sistemi Entegrasyonu yalnızca veri aktarmak için yapılmaz. Asıl amaç, izin verisinin doğru, güncel ve denetlenebilir olmasını sağlamaktır.
Yanlış senkronizasyon, geciken ret işleme veya eksik izin kaydı; hem operasyonel sorun hem de marka riski oluşturur. Bu yüzden entegrasyon süreci, pazarlama ve yazılım ekiplerinin ortak konusu haline gelir.
Başlıca kazanımlar
- SMS izin süreçleri tek panel mantığıyla izlenir.
- E-posta abonelik onayları daha düzenli yönetilir.
- Ret ve iptal talepleri daha hızlı işlenir.
- Kampanya verisi ile izin verisi daha tutarlı ilerler.
- Denetim ve raporlama süreçleri kolaylaşır.
Kimler İYS entegrasyonuna ihtiyaç duyar?
Aşağıdaki yapıdaki işletmeler için IYS entegrasyonu kritik hale gelir:
- CRM, e-ticaret ve toplu mesaj sistemini aynı anda kullanan firmalar
- Birden fazla form, landing page veya bayi ağı üzerinden izin toplayan markalar
- SMS izin süreçleri manuel takip edilen ekipler
- Pazarlama otomasyonu ile müşteri verisini senkron tutmak isteyen işletmeler
- IYS Entegrasyon desteği arayan ve yerel çözüm ortağı ile çalışmak isteyen şirketler
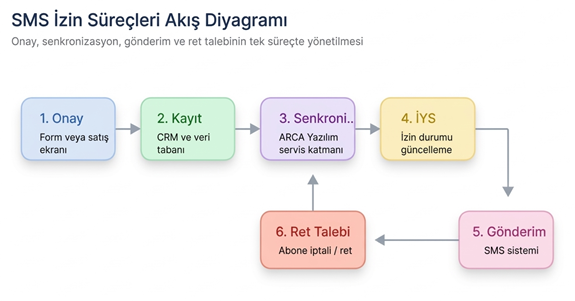
SMS izin süreçleri nasıl yönetilmelidir?
SMS tarafında en kritik konu, onayın ne zaman, hangi metinle ve hangi kaynaktan alındığının ispatlanabilir olmasıdır. Bu veri sadece pazarlama listesinde değil, ana müşteri kaydında da görünmelidir.
Bir kullanıcının ret talebi verdiği anda, bu değişiklik yalnızca SMS platformunda kalmamalıdır. CRM, satış paneli, çağrı merkezi ekranı ve gerekiyorsa e-posta otomasyonu da güncel durumu görmelidir.
Önerilen akış
- Kullanıcı web formu, satış ekranı veya fiziksel onay noktası üzerinden izin verir.
- Onay kaydı CRM veya ana veri tabanına düşer.
- Entegrasyon katmanı veriyi İYS ile eşleştirir.
- SMS platformu yalnızca güncel izinli listeleri kullanır.
- Ret talebi geldiğinde tüm sistemlerde durum eş zamanlı güncellenir.
E-posta izin yönetiminde sık yapılan hatalar
E-posta tarafında çoğu sorun, farklı listelerin birbirinden kopuk tutulmasından doğar. Form verisi başka yerde, bülten sistemi başka yerde, ret kayıtları ise ayrı bir dosyada tutulduğunda hata kaçınılmaz olur.
Kısa vadede çalışan bu yapı, kampanya sayısı arttıkça kırılgan hale gelir. Özellikle otomasyon senaryolarında eski izin verisinin kullanılması ciddi problem yaratır.
En sık karşılaşılan hatalar
- Tekil müşteri kaydı yerine dağınık liste mantığıyla ilerlemek
- Ret talebini yalnızca gönderim aracında işlemek
- Zaman damgası ve kaynak bilgisini saklamamak
- API hata kayıtlarını izlememek
- Test ve canlı ortam verilerini karıştırmak
ARCA Yazılım IYS entegrasyonu yaklaşımı
ARCA Yazılım IYS projelerinde konuya yalnızca “API bağlama” olarak bakmaz. Sağlıklı sonuç için iş akışı, veri modeli ve kullanıcı senaryosu birlikte ele alınmalıdır.
Özellikle özel yazılım altyapısı kullanan firmalarda, tek tip paket çözüm yerine ihtiyaca göre kurgulanmış entegrasyon daha sürdürülebilir olur. Bu nedenle proje başlangıcında veri akış haritası çıkarılması önemlidir.
ARCA Yazılım’ın odaklandığı başlıklar
- Mevcut veri kaynaklarının analizi
- İzin toplama noktalarının standardizasyonu
- İleti Yönetim Sistemi Entegrasyonu için güvenli servis katmanı kurulumu
- SMS izin süreçleri ve ret yönetimi için otomatik senaryolar
- Raporlama, loglama ve hata izleme mekanizması
İYS entegrasyonu projesi nasıl ilerler?
Başarılı bir proje genellikle dört aşamada ilerler. Süreç net tanımlandığında hem geliştirme maliyeti hem de canlıya geçiş riski düşer.
1) Analiz ve veri haritalama
İlk adımda izin verisinin hangi sistemlerde tutulduğu belirlenir. Formlar, CRM, ERP, e-ticaret altyapısı ve mesajlaşma araçları tek tek değerlendirilir.
2) Teknik tasarım
Bu aşamada entegrasyon yönü, servis yapısı, log politikası ve hata senaryoları netleştirilir. Senkron ve asenkron akışlar ayrı ayrı planlanır.
3) Geliştirme ve test
API bağlantıları, veri eşleştirme kuralları ve ret işleme senaryoları geliştirilir. Ardından test verisi ile uçtan uca doğrulama yapılır.
4) Canlıya geçiş ve izleme
Canlı ortamda ilk günler kritik önemdedir. Log takibi, başarısız kayıtlar ve olası uyumsuzluklar düzenli izlenmelidir.
İYS entegrasyonu ile hangi iç süreçler iyileşir?
Doğru kurulan entegrasyon yalnızca mevzuat tarafını değil, günlük operasyonu da iyileştirir. Satış, pazarlama ve müşteri hizmetleri aynı izin gerçekliğine bakar.
Bu da gereksiz liste temizliği, kampanya iptali ve müşteri şikayeti gibi sorunları azaltır. Ekipler veri düzeltmek yerine değer üreten işe odaklanır.
İyileşen başlıklar
- Kampanya hedefleme doğruluğu
- Ret yönetiminde hız
- Müşteri kayıt kalitesi
- Veri tutarlılığı
- Operasyonel görünürlük
İlgili hizmetler
İYS projesi çoğu zaman tek başına ilerlemez. Eğer mevcut altyapınızda özel geliştirme ihtiyacı varsa özel yazılım projesi geliştirme hizmetlerimize göz atabilirsiniz.
Farklı sistemleri konuşturmanız gerekiyorsa entegrasyon çözümlerimiz, kampanya süreçlerinizi güçlendirmek istiyorsanız SMS ve e-posta otomasyon hizmetlerimiz bu projeyi destekleyebilir.
Sık sorulan sorular
İYS entegrasyonu zorunlu mu?
İYS ile ilişkili yükümlülüklerin kapsamı, işletmenin ileti gönderim modeli ve süreçlerine göre değerlendirilmelidir. Ancak ticari elektronik ileti süreçlerinde izin verisinin merkezi ve düzenli yönetilmesi kritik önemdedir.
SMS izin süreçleri neden ayrı ele alınmalıdır?
Çünkü SMS tarafında ret dönüşü ve kampanya sıklığı daha hızlı etki yaratır. Hatalı bir liste kullanımı, kısa sürede çok sayıda kullanıcıyı etkileyebilir.
IYS Entegrasyon desteği alırken nelere bakılmalı?
Sadece API bağlantısı değil; veri modelleme, loglama, hata yönetimi ve canlı sonrası destek planı da değerlendirilmelidir. Yerel iletişim ve hızlı teknik koordinasyon da önemli avantaj sağlar.
ARCA Yazılım IYS projelerinde hangi yapılara destek verebilir?
Özel CRM, e-ticaret altyapısı, form sistemleri, bayi panelleri ve kampanya yönetim araçları gibi farklı yapılara özel entegrasyon senaryoları geliştirilebilir.
Sonuç
İYS entegrasyonu, izin verisini yalnızca saklayan değil yöneten bir işletme yapısı kurmanızı sağlar. Özellikle SMS izin süreçleri ve e-posta onay akışları büyüdükçe, manuel takip sürdürülebilir olmaktan çıkar.
ARCA Yazılım IYS yaklaşımıyla planlanan doğru bir proje; teknik entegrasyonu, veri doğruluğunu ve operasyonel güveni aynı potada birleştirir. Eğer işletmeniz için uygun mimariyi netleştirmek istiyorsanız, daha fazla bilgi almak için resmi web sitesini ziyaret edebilirsiniz: www.arcayazilim.com

Power BI Performans Optimizasyonu: Modelleme, Star Schema, Aggregation ve Hızlandırma Teknikleri
Power BI raporları ilk günlerde “uçuyor” gibi hissedilir. Veri azdır, sayfa sayısı azdır, ölçüler basittir. Zamanla veri büyür, kullanıcı sayısı artar, raporlar çoğalır ve bir noktada kaçınılmaz şikâyet gelir: “Filtre değişince rapor bekletiyor.”
Buradaki kritik gerçek şu: Power BI performansı tek bir ayarla düzelmez. Performans; modelleme, ilişkiler, veri hazırlama (Power Query), DAX, yenileme (refresh) ve rapor tasarımı gibi katmanların toplamıdır. Bu yazıda, özellikle kurumsal projelerde en çok fark yaratan dört başlığa odaklanacağız:
- Modelleme yaklaşımı
- Star Schema (yıldız şema)
- Aggregation (özet tablolar)
- Hızlandırma teknikleri (DAX, tasarım, refresh, mod seçimi)
Hedefimiz net: daha hızlı açılan sayfalar, daha seri filtre tepkileri, büyüdükçe bozulmayan bir mimari.

Power BI Neden Yavaşlar? (Kök Nedenleri Doğru Teşhis Edin)
Power BI’daki yavaşlığın tipik kaynakları genelde şuralardan çıkar:
1) Veri hazırlama (Power Query) ve kaynak sorguları
- Gereksiz kolonlar çekilir, model şişer
- Ağır dönüşümler Power BI tarafında yapılır (kaynak yerine)
- Query Folding bozulur, veri çekme süresi uzar
2) Model katmanı (VertiPaq + ilişkiler)
- Star schema yerine “karma model” kurulur
- Çok sayıda tablo, belirsiz join yolları
- Çift yönlü ilişkiler (Both) kontrolsüz kullanılır
- Yüksek kardinalite (çok benzersiz değer) kolonlar modeli ağırlaştırır
3) DAX (measure) katmanı
- Gereksiz iterasyon (SUMX, FILTER)
- Aynı hesaplar tekrar tekrar yaptırılır
- Filtre bağlamı gereksiz büyür
4) Rapor tasarımı
- Bir sayfada aşırı görsel (15–25+), hepsi etkileşimli
- Çok fazla slicer, cross-highlighting
- Detay tablolar tek sayfada “her şey” olarak sunulur
Bu yüzden performans optimizasyonu, “önce ölç – sonra düzelt” disiplinidir.
Önce Ölçün: Performans Sorunu Nerede?
Optimizasyona başlamadan önce “sorun nerede”yi bulun. Pratik yaklaşım:
- Sayfa mı yavaş? (ilk açılış)
- Filtre mi yavaş? (slicer değişince)
- Görsel mi yavaş? (özellikle matrix/tablo)
- Refresh mi yavaş? (yayınlama sonrası yenileme)
Power BI Desktop’ta en basit ve etkili başlangıç:
- Performance Analyzer ile hangi görselin ne kadar süre aldığını görün.
- Eğer DAX şüphesi varsa, ölçüleri sadeleştirmek için “ölçü bazlı” ilerleyin.
- Eğer model şüphesi varsa, tablo/kolon/ilişki tasarımına dönün.
Performansın Temeli: Doğru Modelleme Mantığı
Power BI’ın Import modunda performans motoru VertiPaq’tır (kolon bazlı sıkıştırma). VertiPaq en iyi performansı şu koşullarda verir:
- Fakt tablolar (transaction/hareket) net ve sade
- Boyut tablolar (dimension) tekrar kullanılabilir
- İlişkiler tek yönlü, anlaşılır
- Model “okunaklı” ve tahmin edilebilir
Bu noktada Star Schema devreye girer.
Star Schema Nedir ve Neden Power BI’ı Hızlandırır?
Star Schema (yıldız şema), BI dünyasında performans ve sürdürülebilirlik için en sık kullanılan modelleme yaklaşımıdır.
Star Schema yapısı
- Ortada Fact: satış satırları, fatura satırları, stok hareketleri, log kayıtları gibi “olay” tablosu
- Etrafında Dimension: Tarih, ürün, müşteri, depo, bölge, personel gibi “tanım” tabloları
Altın kural: Filtreler Dimension’dan Fact’e akar.
Power BI’da star schema performansı neden iyidir?
- Join yolları netleşir, belirsizlik azalır
- Filtre bağlamı daha küçük ve daha hızlı çalışır
- DAX ölçüleri daha az “çapraz tablo” işi yapar
- Model büyüdükçe yönetim kolaylaşır
Sık yapılan hata: “Her tabloyu bağlayalım”
Özellikle operasyonel sistemden gelen tabloları doğrudan rapora atıp “hepsi birbirine bağlı” model kurmak, kısa vadede hızlı başlar ama uzun vadede:
- performansı düşürür,
- doğru sonuç üretmeyi zorlaştırır,
- bakım maliyetini artırır.
İlişki Ayarları: Tek Yön, Doğru Kardinalite, Temiz Anahtar
Modeliniz star schema olsa bile ilişkiler yanlışsa performans yine düşer.
1) Kardinalite (1:* ilişkisi standard)
- Dimension tablosunda anahtar kolon benzersiz olmalı (ProductId gibi)
- Fact tablosunda aynı anahtar çok satırda geçer
Uyarı: Dimension anahtarınız benzersiz değilse many-to-many başlar ve performans/Doğruluk riski artar.
2) Cross filter direction: Varsayılan “Single”
Çift yön (Both) ilişki bazen işleri kolaylaştırır gibi görünür; fakat çoğu kurumsal raporda:
- filtre bağlamını büyütür,
- beklenmedik sonuçlar çıkarabilir,
- performansı düşürür.
Pratik kural:
- %80 senaryoda: Single
- Zorunluysa: kontrollü “Both” ya da DAX ile bilinçli yönlendirme
3) Tarih tablosu (Date dimension) şart
Kurumsal raporlarda tek bir Date tablosu kullanmak hem performansı hem yönetimi kolaylaştırır:
- aynı tarihle ilgili tüm hesaplar tek yerde,
- Year/Quarter/Month/Week gibi kolonlar hazır,
- time intelligence daha stabil.

Modeli Hafifletin: En Hızlı Kazanım Buradan Gelir
Power BI performansında “en hızlı ve net” fark yaratan işlerden biri: modeli zayıflatmak (gereksizi atmak).
Kolonları budayın (Column diet)
- Raporlarda kullanılmayan kolonları modele almayın
- Özellikle fact tablolarda “açıklama/metin” kolonları şişirir
- “Belki lazım olur” kolonları RAM ve hız maliyetidir
Veri tiplerini düzeltin
- Sayısal değer string olmasın
- Tarihler Date/DateTime olarak doğru dursun
- ID kolonları mümkünse integer key ile daha iyi sıkışır
Yüksek kardinaliteyi yönetin
GUID, TransactionId, uzun metin alanları gibi çok benzersiz kolonlar sıkıştırmayı bozar. Çözümler:
- Gereksiz unique kolonları kaldırın
- Metinleri dimension’a taşıyın veya raporda kullanmayın
- “İş için şart değilse” fact’te tutmayın
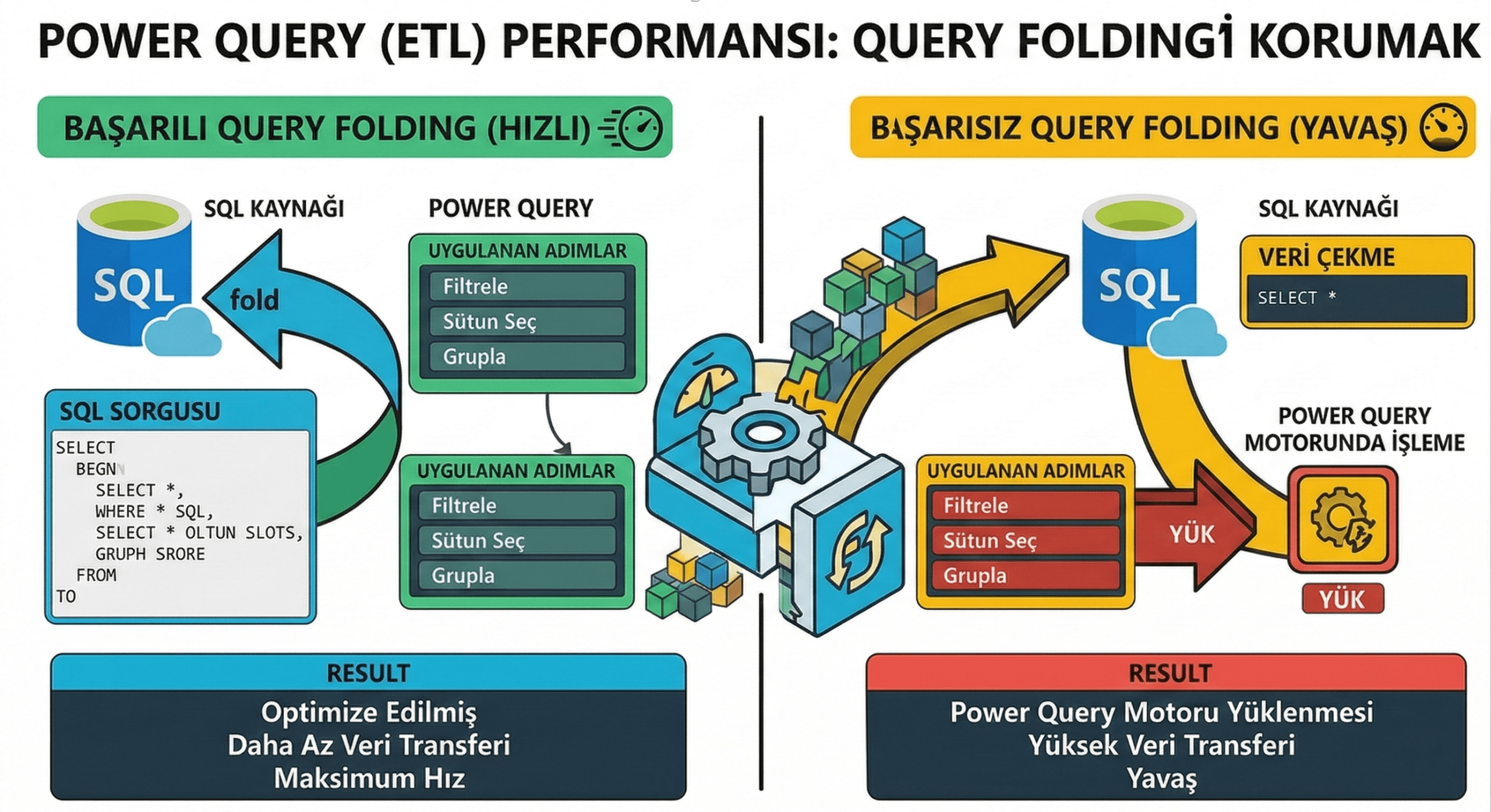
Power Query (ETL) Performansı: Query Folding’i Korumak
Power Query güçlüdür ama yanlış kullanılırsa performansı öldürür.
Query Folding neden önemli?
Folding varsa Power BI dönüşümleri kaynağa “ittirir” (SQL Server’da çalışır). Folding yoksa Power BI her şeyi kendi üstünde işler: daha yavaş, daha maliyetli.
Folding’i bozan tipik durumlar:
- ağır custom dönüşümler,
- bazı join/dönüşüm kombinasyonları,
- gereksiz satır satır işlemler.
İyi pratik:
- ağır dönüşümleri mümkünse kaynakta çözün (view / DWH katmanı)
- Power Query’yi “hafif temizlik ve şekillendirme” için kullanın
DAX Hızlandırma: Ölçüler Neden Yavaşlar ve Nasıl İyileştirilir?
DAX performansı çoğunlukla iki şeyle ilgilidir:
- Ne kadar satır dolaşıyorsunuz? (iterasyon)
- Filtre bağlamı ne kadar karmaşık?
1) Gereksiz iterasyondan kaçının
SUMX/FILTER gibi fonksiyonlar bazı senaryolarda şarttır ama “refleks” gibi kullanılırsa pahalıdır.
Kendinize sorun:
Bu hesap gerçekten satır satır mı yapılmalı, yoksa agregasyonla çözülebilir mi?
2) VAR kullanın: aynı işi tekrar yaptırmayın
Aynı ara sonucu 2–3 kez hesaplatmak yerine bir kez hesaplatıp tekrar kullanmak çoğu raporda hissedilir fark yaratır.
3) Filtreyi modele taşıyın
Her ölçünün içinde aynı filtre kalıbı dönüyorsa, bu genelde modelleme ile daha sade hale getirilebilir:
- flag kolonlar,
- doğru dimension ilişkileri,
- daha doğru granülerlik.
Aggregation: Büyük Veride “Turbo” Etkisi
Power BI’da milyonlarca satırlık fact tabloyla çalışırken asıl mesele şudur:
Kullanıcıların çoğu zaman detay değil özet görmesi gerekir.
Aggregation (özet tablolar) burada devreye girer.
Aggregation ne sağlar?
- Kullanıcı aylık trend bakarken 50 milyon satırı taramak zorunda kalmaz
- Özet tablo üzerinden “hızlı cevap” alınır
- Detay gerekiyorsa drill-down/drill-through ile detay fact’e gidilir
Ne zaman aggregation şart olur?
- Fact tablo çok büyükse (milyonlar+)
- Raporlar ağırlıkla “gün/ay/ürün kategori/bölge” düzeyinde çalışıyorsa
- Kullanıcı sayısı fazlaysa ve kapasite yönetimi önemliyse
Basit aggregation tasarım reçetesi
- Kullanıcıların en çok baktığı seviyeleri çıkarın: Ay, Bölge, Kategori
- Bu seviyede özet tablo üretin (örn. AylıkSatışÖzet)
- Modelde hem özet hem detay fact’i tutun
- Özet sayfaları özet tablodan, detay sayfaları büyük fact’ten besleyin
Bu yaklaşım, “sadece hız” değil aynı zamanda ölçeklenebilirlik kazandırır.
Incremental Refresh: Yenilemeyi Hızlandırın, Kaynağı Yormayın
Performans sadece rapor açılışı değildir. Refresh süresi uzadıkça:
- kapasite meşgul olur,
- kaynak sistem (SQL/ERP) zorlanır,
- rapor güncelliği riske girer.
Incremental Refresh ile:
- Son X gün/ay sık yenilenir
- Geçmiş veri “dokunulmadan” saklanır
- Yenileme süreleri dramatik şekilde düşer
Özellikle log/transaction verisi büyüyorsa incremental refresh çoğu zaman “olmazsa olmazdır”.
Import vs DirectQuery vs Composite: Doğru Modu Seçin
Yanlış mod seçimi, en iyi modellemeyi bile boşa çıkarabilir.
Import
- En hızlı kullanıcı deneyimi
- RAM kullanır
- Çoğu dashboard senaryosu için ideal
DirectQuery
- Kaynağa anlık gider
- Kaynak iyi tasarlanmadıysa (indeks, view, sorgu) yavaşlar
- “Her görsel = yeni sorgu” maliyetini düşünmek gerekir
Composite (Import + DirectQuery)
- Bazı tablolar import ile hızlı
- Bazıları direct ile güncel
- Kurumsal yapılarda sık kullanılan dengeli yaklaşım
Pratik kural:
“Hız ve kullanıcı deneyimi” öncelikse → Import + iyi modelleme + aggregation
“Anlık veri” kritikse → Composite / kontrollü DirectQuery
Rapor Tasarımıyla Hızlandırma: Görsel Sayısını ve Etkileşimi Yönetin
Modeliniz mükemmel olsa bile, rapor sayfası “aşırı yük” taşıyorsa yavaşlar.
Tasarım için performans kuralları
- Bir sayfada görsel sayısını makul tutun (genelde 8–12 bandı iyidir)
- Çok sayıda slicer yerine “filtre paneli” yaklaşımı düşünün
- Cross-highlighting/cross-filtering etkileşimlerini gerektiği kadar açık bırakın
- Büyük detay tablolarını ayrı sayfaya taşıyın (drill-through)
Özet + Detay mimarisi
- Özet sayfalar: hızlı, KPI odaklı
- Detay sayfalar: filtrelenmiş, amaçlı analiz
Bu yaklaşım hem performansı hem kullanıcı memnuniyetini artırır.
10 Dakikada Hız Kazandıran Kontrol Listesi (Quick Wins)
Hızlı bir iyileştirme turu yapmak isterseniz:
- Kullanılmayan kolonları modelden kaldırdım
- Metin/GUID ağırlıklı kolonları fact’ten temizledim
- İlişkileri çoğunlukla Single yaptım
- Many-to-many ilişkileri azalttım / kontrol altına aldım
- Date dimension kullandım
- Slicer sayısını azalttım, sayfayı sadeleştirdim
- En yavaş görseli Performance Analyzer ile tespit ettim
- En pahalı DAX ölçülerini VAR ile sadeleştirdim
Bu checklist bile çoğu projede “ilk etap”ta hissedilir fark yaratır.

Sonuç: Power BI Performansı “Şans” Değil, Mimari İşidir
Power BI performans optimizasyonu; rastgele ayarlarla değil, doğru modelleme ve doğru strateji ile çözülür. Star schema ile sadeleşen model, kontrollü ilişkiler, temiz veri hazırlama, iyi DAX pratikleri ve gerektiğinde aggregation/incremental refresh gibi teknikler birleştiğinde:
- Raporlar hızlı açılır
- Filtreler seri tepki verir
- Veri büyüdükçe sistem bozulmaz
- Kullanıcı sayısı artsa bile yönetilebilir kalır
Sıradaki Okumalar (İç Link Önerileri)
Web sitende aynı formatta şu içeriklerle birbirine linkleyebilirsin:
- DAX Rehberi: En Sık Kullanılan Measure Desenleri
- SSRS vs Power BI: Hangi Senaryoda Hangisi?
- SSIS ile ETL Performans Optimizasyonu: Incremental Load ve Hata Yönetimi
CTA (İletişim / Hizmet Metni)
Power BI raporlarınız yavaşsa, çoğu zaman sorun tek yerde değildir: model + DAX + veri + tasarım birlikte ele alınmalıdır. İstersen mevcut raporlarınız için performans analizi çıkarıp, star schema dönüşümü, aggregation planı ve incremental refresh stratejisiyle net bir iyileştirme yol haritası hazırlayabiliriz.
SSAS Tabular vs Power BI Semantic Model: Ne Zaman Hangisi? (Kurumsal Modelleme ve Governance Karar Matrisi)
Kurumsal BI dünyasında “rapor yapmak” asıl mesele değildir; asıl mesele tek doğru veriyi, tek doğru iş tanımıyla (KPI/metric), doğru yetkilendirme ile ve kontrollü bir yaşam döngüsü (dev–test–prod) içinde sürdürülebilir şekilde sunmaktır.
Bu noktada iki güçlü seçenek öne çıkar:
- SSAS Tabular (SQL Server Analysis Services – Tabular Model)
- Power BI Semantic Model (Power BI dataset / model katmanı)
İkisi de aynı temel motor mantığına (tabular modelleme + DAX) dayanır; fakat dağıtım, yönetim, governance ve organizasyonel kullanım şekli açısından ciddi farklar vardır. Bu yazıda, “hangisi daha iyi?” yerine şu soruya net cevap vereceğiz:
“Hangi senaryoda SSAS Tabular, hangi senaryoda Power BI Semantic Model daha doğru tercih olur?”
Ayrıca yazının sonunda, kurumsal karar vermeyi kolaylaştıran bir governance karar matrisi bırakacağım.
Önce Kavramları Netleştirelim
 SSAS Tabular Nedir?
SSAS Tabular Nedir?
SSAS Tabular, merkezi olarak yönetilen bir analitik modelleme katmanıdır.
Genellikle on-prem SQL Server ekosisteminde (veya uyumlu kurumsal altyapılarda) “tek model – çok rapor” yaklaşımını destekler:
- Model bir kez tasarlanır (tabular)
- Çok sayıda rapor/araç (Power BI, Excel, diğer istemciler) bu modeli tüketir
- Yönetim/dağıtım/versiyonlama daha “kurumsal” kurgulanır
Power BI Semantic Model Nedir?
Power BI Semantic Model, Power BI Service içinde yayınlanan ve yönettiğiniz dataset/model katmanıdır.
Aynı şekilde:
- Tablo ilişkileri
- DAX measure’lar
- RLS/OLS
- KPI’lar ve hiyerarşiler
gibi semantik katman unsurlarını içerir.
Power BI Semantic Model’in kritik avantajı:
Power BI ekosistemi ile uçtan uca entegre olmasıdır (workspace, deployment pipeline, lineage, usage metrics vb.).
Ortak Noktalar: Aslında Aynı Dünyanın İki Yüzü
İkisi de pratikte benzer şeyleri yapar:
- Boyut-fakt modelleme (star schema)
- DAX ölçüleri
- Veri yenileme (refresh)
- RLS/OLS gibi güvenlik
Bu yüzden seçim çoğu zaman “teknik olarak hangisi yapabiliyor?” değil, şu eksende olur:
- Yönetim modeli (kim yönetiyor, nasıl yayınlanıyor?)
- Governance (tek doğruluk, standardizasyon, denetim)
- Dağıtım ve ALM (dev/test/prod, sürümleme)
- Performans ve ölçek (kapasite, concurrent kullanıcı)
- Güvenlik ve erişim kontrolü
- Maliyet ve lisans (organizasyonun gerçekleri)
Kurumsal Modelleme Neden “Semantic Layer” İster?
Kurumsal ortamlarda en büyük problem şudur:
Aynı KPI farklı raporlarda farklı hesaplanır.
Örnek:
- “Net Satış” bir raporda iade düşülmüş
- başka raporda düşülmemiş
- tarihler birinde “fatura tarihi”, diğerinde “sipariş tarihi”
Bu durum hem güven kaybı yaratır hem de yönetimi zorlaştırır.
İşte SSAS Tabular veya Power BI Semantic Model, bu problemi “semantic layer” olarak çözer:
- KPI tanımı tek yerde durur
- raporlar aynı ölçüleri kullanır
- governance oturur
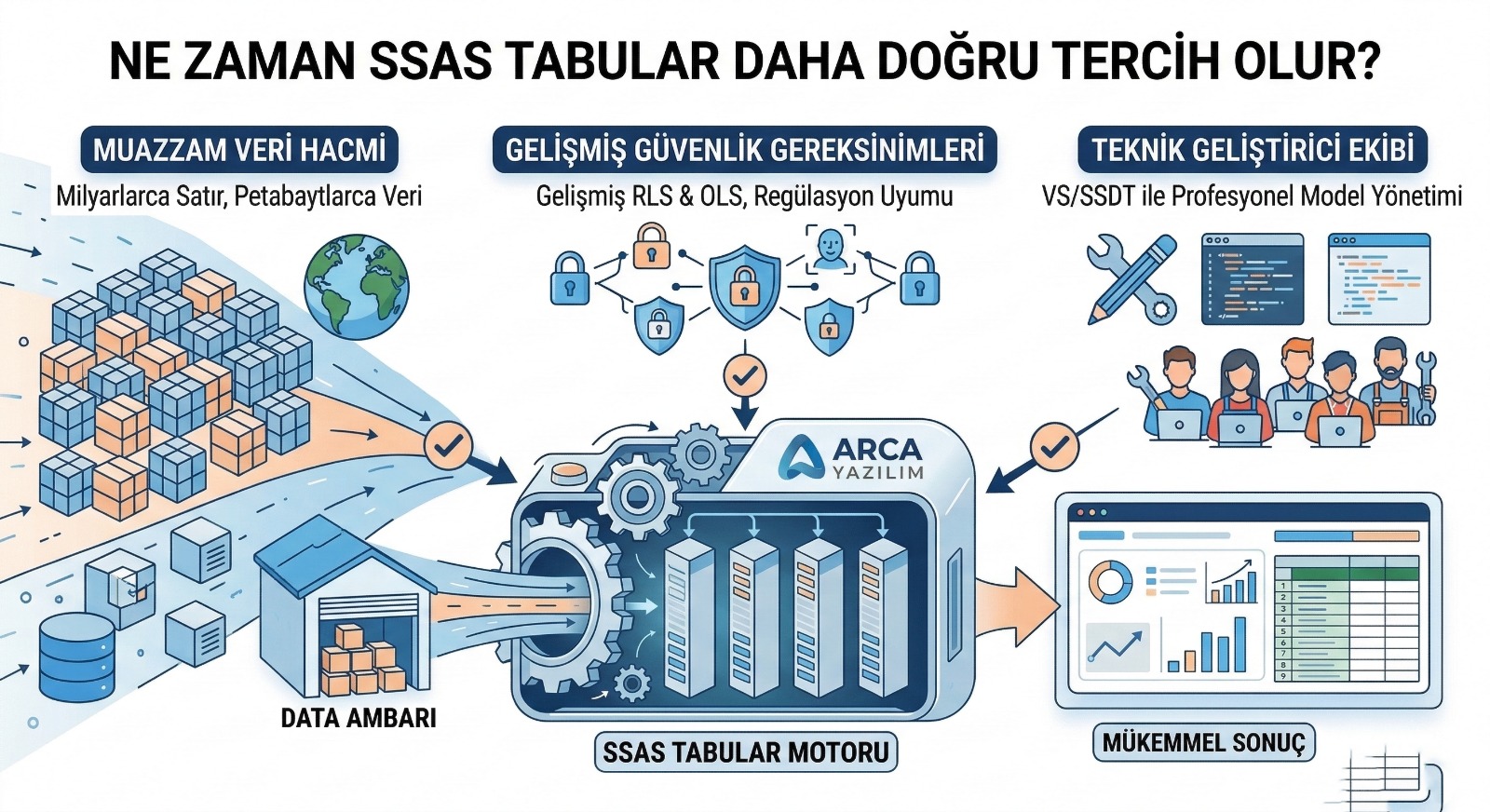
Ne Zaman SSAS Tabular Daha Doğru Tercih Olur?
SSAS Tabular genellikle şu durumlarda öne çıkar:
1) “Merkezi BI” kültürü güçlü ise
Kurumun BI ekibi:
- modelleri merkezden yönetiyorsa,
- rapor tüketimi farklı araçlara yayılıyorsa (Excel Pivot, üçüncü parti araçlar vb.),
SSAS Tabular daha doğal bir “tek model – çok tüketici” omurgası olur.
2) On-prem ağırlıklı altyapı ve sıkı kontrol ihtiyacı varsa
Bazı kurumlar güvenlik/regülasyon nedeniyle:
- veriyi buluta taşımak istemez
- her şeyi data center’da tutar
Bu tip yapılarda SSAS Tabular, klasik Microsoft BI mimarisine çok iyi oturur.
3) Power BI dışında da yoğun tüketim varsa
Sadece Power BI değil:
- Excel + Pivot
- özel uygulamalar
- diğer analitik istemciler
SSAS Tabular’ın “merkezi servis” olma avantajı artar.
4) Model yaşam döngüsü ağır ve kontrollüyse
Release süreçleri:
- ITIL / change management
- sıkı dev/test/prod kapıları
gerektiriyorsa SSAS, “kurumsal release” disiplinine daha uyumlu kurgulanabilir.
Ne Zaman Power BI Semantic Model Daha Doğru Tercih Olur?
Power BI Semantic Model genellikle şu durumlarda daha avantajlıdır:
1) Power BI kurumun ana BI platformuysa
Raporların çoğu Power BI ile üretilip tüketiliyorsa:
- dataset yönetimi
- workspace yapısı
- deployment pipeline
- lineage ve kullanım metrikleri
tamamen Power BI tarafında daha akıcı çalışır.
2) Self-service BI önemliyse
Farklı departmanların (satış, pazarlama, operasyon) hızlı rapor üretmesi gereken yapılarda:
- veri seti paylaşımı
- certified/promoted dataset yaklaşımı
- reuse kültürü
Power BI Semantic Model çok pratik bir governance çerçevesi sunar.
3) Bulut / modern ekosistem hedefleniyorsa
Azure, Fabric, modern data platformu gibi hedeflerde Power BI Semantic Model doğal durur.
Özellikle “rapor + dataset + governance” üçlüsünü tek yerde yönetmek isteyen kurumlar için.
4) Deployment ve ALM’i Power BI üzerinden yönetmek istiyorsanız
Power BI tarafında:
- workspace bazlı yaşam döngüsü
- deployment pipeline
- semantic model refresh yönetimi
genelde daha hızlı ve operasyonel olarak daha kolaydır.
Güvenlik ve Yetkilendirme: RLS/OLS ve Kurumsal Kontroller
Her iki tarafta da RLS yapılabilir; ancak kurumsal kararda şu sorular belirleyicidir:
- Kullanıcılar Azure AD üzerinden mi yönetiliyor?
- Rol yönetimi merkezi mi?
- Çok firmalı (multi-tenant) raporlama var mı?
- Kim dataset/model üzerinde değişiklik yapabiliyor?
Power BI Semantic Model tarafında governance için çok kritik iki yaklaşım:
- Certified Dataset (kurumun “tek doğrusu”)
- Workspace izinleri + dataset build izinleri
SSAS tarafında ise daha klasik ama merkezi bir kontrol:
- IT/BI ekibi model üzerinde sıkı yönetim
- istemciler sadece “tüketici”
Performans ve Ölçek: “Aynı Anda Çok Kullanıcı” Meselesi
Kurumsal raporlarda performansı belirleyen şey sadece model değil; aynı zamanda:
- eş zamanlı kullanıcı sayısı
- kapasite / kaynak yönetimi
- yenileme planları
- dataset boyutu
Power BI Semantic Model’de ölçek
- Kapasite (özellikle premium) üzerinden yönetim güçlüdür
- Workspace ve pipeline yönetimi pratik
- Kullanım metrikleriyle izleme daha erişilebilirdir
SSAS Tabular’da ölçek
- On-prem kaynaklarınızın gücüyle sınırlı ama kontrol sizde
- Donanım yönetimi, monitoring, tuning kurumsal IT ile yürür
- Çok büyük ve kritik modellerde IT kontrolü avantaj olabilir
Governance Karar Matrisi: Ne Zaman Hangisi?
Aşağıdaki matrisi “tek bakışta karar” gibi düşünebilirsiniz.
1) Öncelik “Merkezi kontrol + çoklu istemci” ise → SSAS Tabular
- Power BI dışı tüketim yüksek (Excel vb.)
- On-prem zorunluluğu var
- Model değişiklikleri sıkı change yönetimi gerektiriyor
- BI ekipleri merkezi ve baskın
2) Öncelik “Power BI ekosistemi + self-service + hızlı dağıtım” ise → Power BI Semantic Model
- Raporların çoğu Power BI’da
- Departmanlar hızlı içerik üretmek istiyor
- Certified dataset kültürü kurulacak
- Pipeline ve workspace yönetimi önemli

Örnek Mimari Senaryolar
Senaryo A: Kurumsal Merkezî Model (SSAS Tabular omurga)
- SQL Server DWH (Gold katman, star schema)
- SSAS Tabular model (tek semantik katman)
- Power BI + Excel + diğer istemciler aynı modeli tüketir
Avantaj: Tek model, tek KPI, yüksek kontrol
Dikkat: Değişim süreci genelde daha “ağır” olur
Senaryo B: Power BI Merkezli Kurumsal BI (Semantic model omurga)
- DWH/Lakehouse (gold katman)
- Power BI Semantic Model (Certified dataset)
- Workspace + deployment pipeline ile dev/test/prod
- Raporlar aynı dataset üzerinden çoğaltılır
Avantaj: Power BI’da uçtan uca yönetim
Dikkat: Dataset sprawl (herkes kendi datasetini çıkarır) riskine governance gerekir
Senaryo C: Hibrit (Sık görülen gerçek hayat)
- Kritik kurumsal KPI’lar: merkezi semantic model (SSAS veya certified Power BI dataset)
- Departman raporları: self-service (governed) datasetler
- İhtiyaca göre iki katmanlı semantic layer
Avantaj: Hem kontrol hem çeviklik
Dikkat: Sınırları iyi çizmek gerekir (hangi KPI nerede “tek doğru”?)
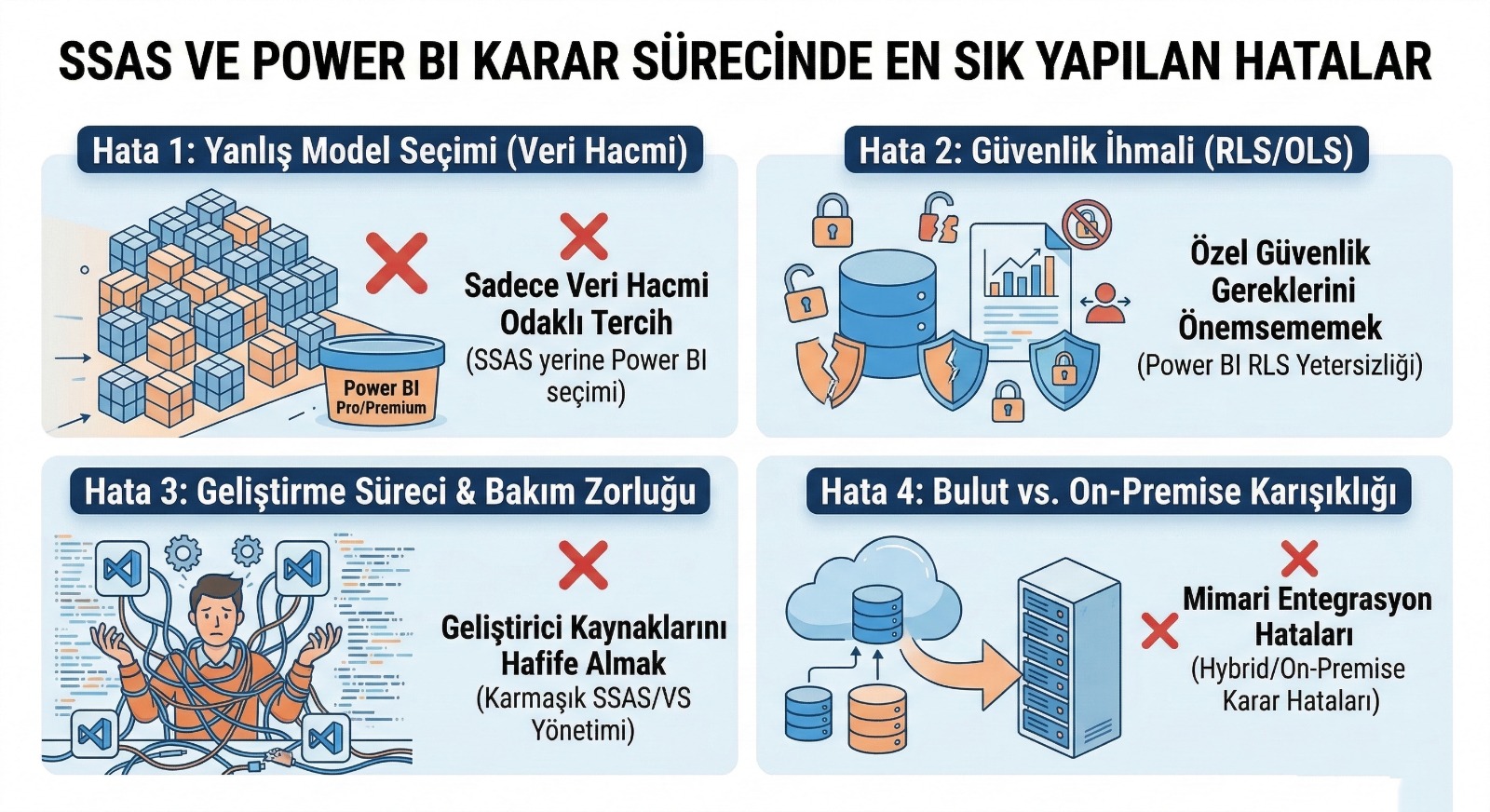
En Sık Yapılan Hatalar (Kaçının)
- Her ekip kendi datasetini çıkarır → aynı KPI farklılaşır
- Certified dataset kültürü kurulmaz → “hangi rapor doğru?” tartışması bitmez
- Star schema yerine operasyonel model kullanılır → performans düşer
- RLS/OLS plansız yapılır → güvenlik açıkları veya aşırı karmaşa
- Dev/test/prod akışı kurulmaz → canlıda deneme yapılır
Sonuç: Doğru Seçim Organizasyon Modeliyle Birlikte Gelir
SSAS Tabular ve Power BI Semantic Model, teknik olarak benzer temellere sahip olsa da kurumsal dünyada seçimi belirleyen şey çoğu zaman şudur:
- Kurumun BI yönetim modeli
- Governance olgunluğu
- Dağıtım ve yaşam döngüsü (ALM)
- Tüketim kanalları (sadece Power BI mı, Excel de var mı?)
- Güvenlik ve regülasyon
- Eş zamanlı kullanıcı ve kapasite planı
Eğer kurum Power BI merkezli çalışıyorsa ve self-service kritikse, Power BI Semantic Model ile “Certified dataset” düzeni kurmak çoğu zaman en verimli yoldur.
Eğer merkezi kontrol, on-prem zorunluluğu ve Power BI dışı tüketim yüksekse, SSAS Tabular hâlâ çok güçlü bir kurumsal omurgadır.
Sıradaki Okumalar (İç Link Önerileri)
- Power BI Performans Optimizasyonu: Modelleme, Star Schema, Aggregation ve Hızlandırma Teknikleri
- ETL Nedir, ELT Nedir? Power BI + SQL + Data Warehouse ile Doğru Mimariyi Seçme Rehberi
- Kurumsal Veri Deposu (DWH) Tasarımı: Kimball Star Schema, SCD ve KPI Sözlüğü
CTA (İletişim / Hizmet Metni)
Kurumunuz için doğru karar, mevcut veri kaynaklarınız, kullanıcı sayınız, güvenlik gereksinimleriniz ve Power BI kullanım biçiminize göre değişir. İsterseniz mevcut yapınızı değerlendirip SSAS Tabular mı, Power BI Semantic Model mi kararını netleştiren bir governance değerlendirmesi ve uygulanabilir bir mimari yol haritası çıkarabiliriz.
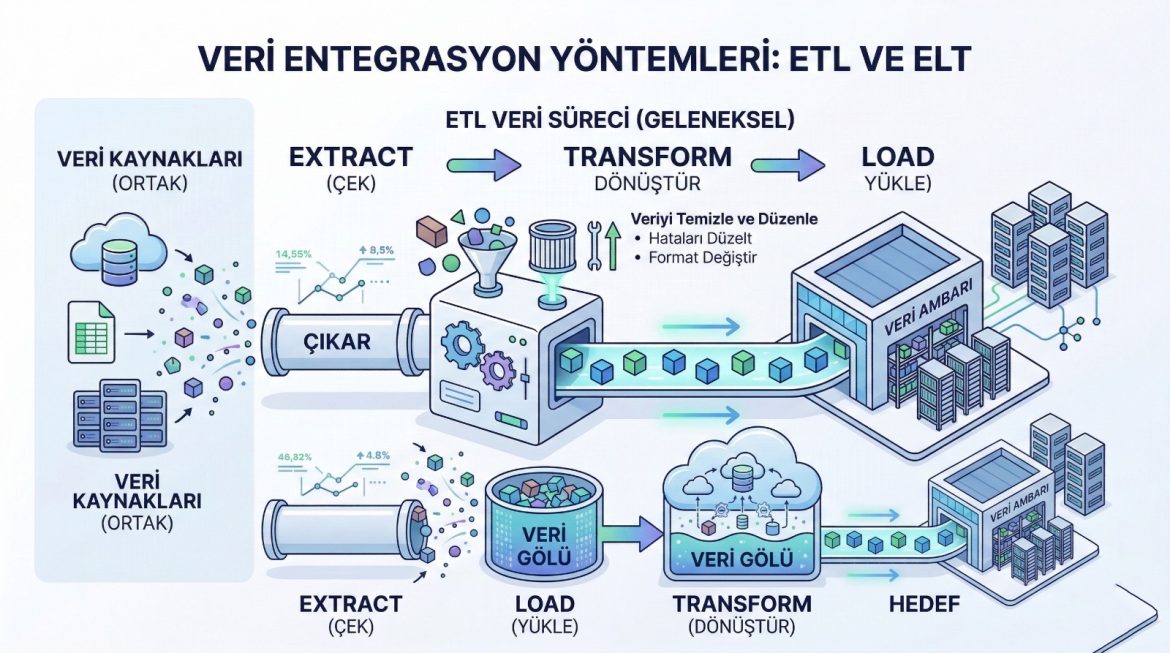
ETL Nedir, ELT Nedir? Power BI + SQL + Data Warehouse ile Doğru Mimariyi Seçme Rehberi
İş zekâsı projelerinde en sık yapılan hatalardan biri, daha en başta yanlış soruyu sormaktır. “ETL mi yapalım ELT mi?” sorusu tek başına eksik kalır. Asıl soru şudur:
“Bizim veri hacmimiz, kaynak sistemlerimiz, ekip yetkinliğimiz, raporlama ihtiyacımız ve güvenlik kısıtlarımız için en sürdürülebilir veri akışı hangisi?”
Çünkü ETL/ELT seçimi; sadece teknik bir tercih değil, doğrudan:
- raporların hızını,
- veri kalitesini,
- operasyon maliyetini,
- geliştirme hızını,
- ve uzun vadede bakım yükünü belirler.
Bu rehberde ETL ve ELT’yi netleştireceğiz; ardından Power BI + SQL + Data Warehouse dünyasında “hangi senaryoda hangisi” sorusuna pratik bir karar çerçevesi vereceğiz.
ETL Nedir?
ETL = Extract (Çek) → Transform (Dönüştür) → Load (Yükle)
Yani veriyi kaynaktan çekersiniz, genellikle bir ETL aracı/servisi üzerinde dönüştürürsünüz, sonra hedef sisteme (Data Warehouse gibi) yüklersiniz.
ETL’nin temel özellikleri
- Dönüşümler yüklemeden önce yapılır
- Hedef veri ambarına “hazır, temiz, kuralı uygulanmış” veri gider
- Veri kalitesi ve kontrol noktaları ETL katmanında toplanır
ETL’nin “klasik” kullanım alanı
- Kurumsal Data Warehouse (DWH) yapıları
- On-prem SQL Server + SSIS benzeri senaryolar
- Sıkı kurallı, denetlenebilir raporlama sistemleri
ELT Nedir?
ELT = Extract (Çek) → Load (Yükle) → Transform (Dönüştür)
Bu yaklaşımda veriyi önce hedef platforma (DWH/Lakehouse) ham veya yarı-ham şekilde yüklersiniz. Dönüşümleri ise hedefin kendi işlem gücüyle (çoğu zaman SQL ile) gerçekleştirirsiniz.
ELT’nin temel özellikleri
- Dönüşümler yüklemeden sonra yapılır
- Hedef platform güçlü işlem kapasitesi sunar (warehouse/lakehouse)
- Ham veriyi saklamak kolaylaşır (yeniden işleme, versiyonlama)
ELT’nin “modern” kullanım alanı
- Bulut tabanlı lakehouse/warehouse mimarileri
- Büyük veri, yarı-yapısal veri (JSON/log vb.)
- Dönüşüm kurallarının hızlı değiştiği ürün/analitik ekipleri
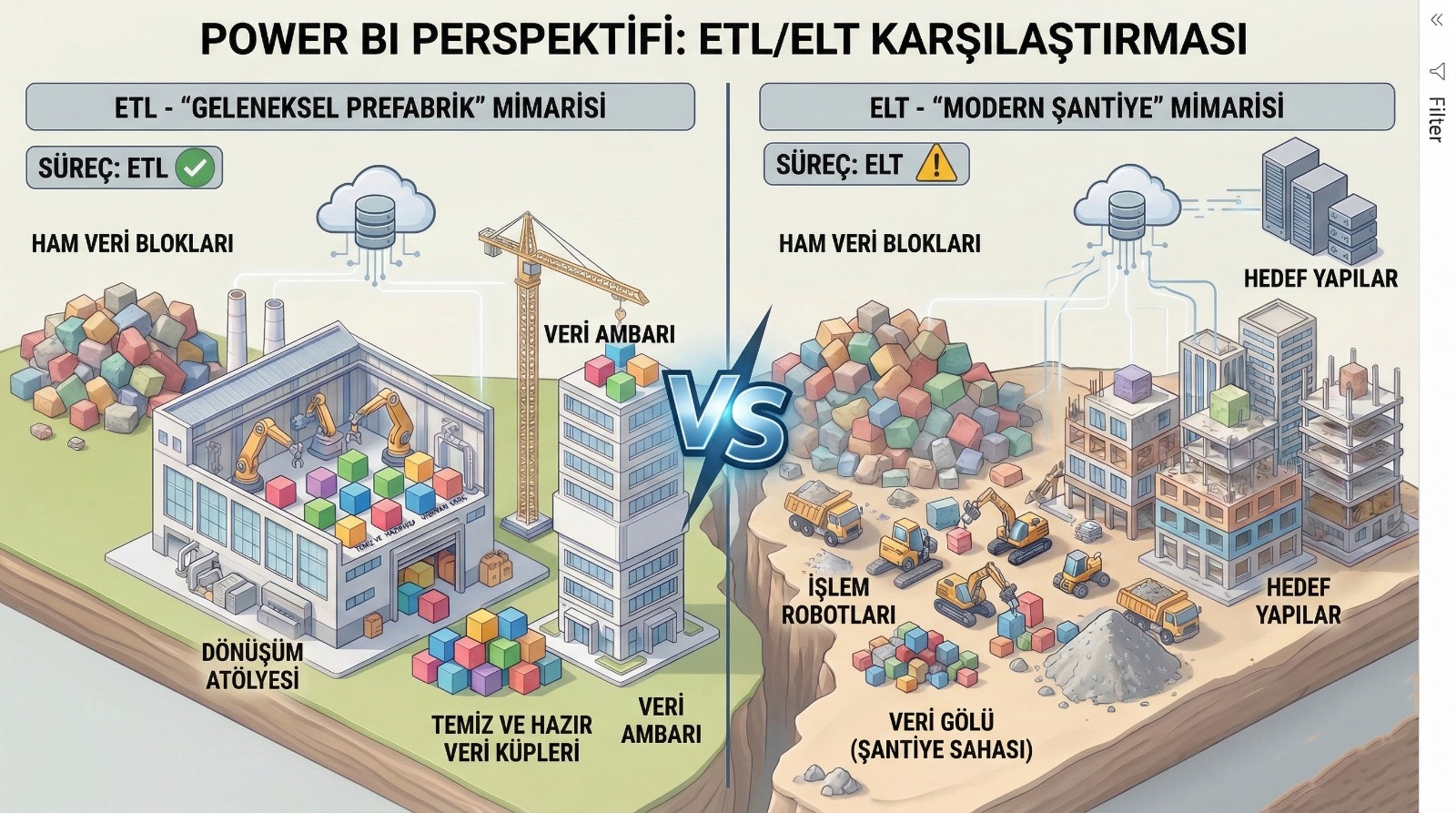
ETL vs ELT: Kısa Karşılaştırma
Aşağıdaki tablo “tek bakışta” farkı oturtur:
| Kriter | ETL | ELT |
| Dönüşüm nerede yapılır? | ETL katmanında | Hedef platformda (DWH/Lakehouse) |
| Hedefe giden veri | Temizlenmiş, kuralı uygulanmış | Ham / yarı-ham + sonra kural |
| Esneklik | Orta | Yüksek |
| Ham veriyi saklama | Genelde sınırlı/opsiyonel | Genelde standart pratik |
| Performans yaklaşımı | ETL katmanı optimize edilir | Warehouse/Lakehouse compute kullanılır |
| Yönetişim (governance) | ETL’de merkezi kontrol | Model katmanlarında disiplin gerekir |
| Hangi ekip daha rahat? | ETL/BI ağırlıklı ekipler | Analytics engineering / SQL ağırlıklı ekipler |
Kısa özet:
ETL daha “kontrollü ve klasik”; ELT daha “esnek ve modern” bir yaklaşımdır. Ama “modern = her zaman doğru” değildir.
Microsoft İş Zekâsı Ekosisteminde ETL ve ELT Nasıl Konumlanır?
Power BI + SQL + DWH dediğimizde pratikte iki ana mimari dünyası görürüz:
1) SQL Server tabanlı klasik DWH (ETL ağırlıklı)
- Kaynaklar: ERP/CRM/operasyon DB’leri
- ETL: SSIS benzeri akışlar / planlı job’lar
- Hedef: SQL Server Data Warehouse (boyut-fakt)
- Sunum: Power BI semantic model / dataset
Bu dünyada ETL doğal oturur: DWH’ye temiz veri yüklersiniz, Power BI modeli hızlı olur.
2) Lakehouse/Warehouse tabanlı modern analitik (ELT ağırlıklı)
- Kaynaklar: DB + API + dosyalar + loglar
- Önce yükle: ham veri “landing/staging” alanına
- Sonra dönüştür: SQL tabanlı dönüşümlerle “gold” katman
- Sunum: Power BI (Import/DirectQuery/Composite) + semantic model
Bu dünyada ELT, “ham veriyi sakla → ihtiyaca göre dönüştür” mantığıyla güçlüdür.
Power BI Perspektifi: ETL/ELT Seçimi Rapor Performansını Nasıl Etkiler?
Power BI performansının temeli genelde şunlara dayanır:
- Modelleme (star schema)
- Veri hacmi ve granülerlik
- Yenileme (refresh) stratejisi
- Import/DirectQuery seçimi
ETL/ELT seçimi bu alanlara doğrudan dokunur:
ETL tarafında avantaj
- DWH katmanı “rapora hazır” olduğu için Power BI modeli daha hızlı kurulur
- Boyut-fakt yapısı netleşir
- Veri kalitesi kuralları önce uygulanır
ELT tarafında avantaj
- Ham veriden başlayıp ihtiyaç oldukça model üretmek kolaydır
- Yeni rapor ihtiyacında “yeniden ETL yazma” yükü azalabilir
- Dönüşümler SQL ile yönetilebildiği için iterasyon hızlıdır
Pratik gerçek:
Power BI tarafında en kritik hedef genelde star schema’dır. ETL de ELT de bu hedefe hizmet edebilir. Önemli olan dönüşümleri nereye koyduğunuzdan çok, sonuçta Power BI’ın beslendiği “gold” katmanın düzgün tasarlanmasıdır.
Hangi Senaryoda ETL Daha Doğru Tercih Olur?
Aşağıdaki durumlar ETL’yi avantajlı yapar:
1) On-prem ve kaynak sistem hassassa
Kaynak sistemleri yormadan, kontrollü yükleme pencereleriyle veri taşımak gerekiyorsa ETL daha düzenlidir.
2) Veri kalitesi ve denetim (audit) kritikse
Finans, muhasebe, regülasyon gibi alanlarda:
- kurallar net,
- değişiklikler kontrollü,
- audit izleri gerekli ise ETL yaklaşımı daha güvenli olur.
3) Dönüşümler çok kompleks ve “pipeline” odaklıysa
Bazı dönüşümler (özellikle çok adımlı iş kuralları) ETL akışında daha yönetilebilir olabilir.
4) Ekip “BI/ETL kültürü” ile güçlü ise
ETL araçlarına hakim ekipler ETL ile daha hızlı ve daha az riskle ilerler.
Hangi Senaryoda ELT Daha Doğru Tercih Olur?
ELT’yi güçlü yapan tipik durumlar:
1) Veri çeşitliliği yüksekse (DB + API + dosya + log)
Ham veriyi önce toplayıp sonra ihtiyaç oldukça dönüştürmek daha esnektir.
2) Dönüşüm kuralları sık değişiyorsa
Ürün analitiği, growth, deneyler, hızlı iterasyon gerektiren yapılarda ELT yaklaşımı daha çeviktir.
3) Hedef platform güçlü işlem kapasitesi sunuyorsa
Warehouse/lakehouse tarafında ölçeklenebilir compute varsa dönüşümü orada yapmak mantıklıdır.
4) “Ham veri” saklamak stratejikse
Geriye dönük yeniden işleme, yeni KPI türetme, veri bilimi/ML ihtiyaçları varsa ham verinin tutulması büyük avantaj sağlar.
Hibrit Yaklaşım: Gerçekte En Çok Kullanılan Model
Sahada çoğu kurum “tam ETL” veya “tam ELT” değildir. En sürdürülebilir yapı genelde hibrittir:
Katmanlı mimari (Bronze / Silver / Gold)
- Bronze (Raw/Landing): Ham veri
- Silver (Clean/Conformed): Temizlenmiş, standardize edilmiş veri
- Gold (Serving): Raporlamaya hazır boyut-fakt, özet tablolar
Bu yaklaşımın güzelliği şudur:
- Ham veri kaybolmaz
- Dönüşümler katman katman yönetilir
- Power BI’a giden “gold” katman performans odaklı tasarlanır
Karar Çerçevesi: ETL mi ELT mi? (7 Soru ile Netleştirin)
Aşağıdaki soruları cevaplayın. “Evet” ağırlığı hangi tarafa kayıyorsa seçim de oraya yaklaşır.
- Kaynak sistem çok hassas mı, ağır sorgu kaldıramıyor mu?
→ Evetse ETL eğilimi artar. - Ham veriyi saklamak zorunlu mu / çok değerli mi?
→ Evetse ELT eğilimi artar. - KPI ve iş kuralları sık değişiyor mu?
→ Evetse ELT eğilimi artar. - Regülasyon / audit / veri doğruluğu kritik mi?
→ Evetse ETL eğilimi artar (veya hibritte “silver/gold” çok disiplinli olmalı). - Ekip hangi tarafta daha güçlü?
- ETL aracı ve pipeline disiplini mi? → ETL
- SQL dönüşüm, model katmanı disiplini mi? → ELT
- Veri hacmi ve çeşitliliği ne durumda?
- Çok kaynak, çok format → ELT/hibrit
- Az kaynak, net şema → ETL
- Power BI’da hedef mod ne?
- Import ile performans hedefleniyorsa → “gold” katmanın sağlam olması şart (ETL veya ELT fark etmez)
- DirectQuery ağırlıksa → kaynak/warehouse optimizasyonu kritik (ELT + iyi SQL tasarım öne çıkar)
Örnek Mimari Senaryolar
Senaryo A: Klasik Kurumsal DWH (ETL ağırlıklı)
Akış:
- Operasyon DB (ERP/CRM)
- Staging alanı
- ETL dönüşümleri (iş kuralları + kalite kontrolleri)
- DWH (Star schema: Fact + Dimension)
- Power BI (semantic model + raporlar)
Ne zaman ideal?
Raporlar net, yönetim KPI’ları stabil, veri yönetişimi güçlü isteniyor.
Senaryo B: Lakehouse/Modern Analitik (ELT ağırlıklı)
Akış:
- Kaynaklar (DB + API + dosya + log)
- Raw/Landing (ham)
- Warehouse/Lakehouse üzerinde SQL dönüşümleri
- Gold katman (boyut-fakt + özet)
- Power BI (import/composite)
Ne zaman ideal?
Çok kaynak var, sürekli yeni ihtiyaç geliyor, hızlı iterasyon şart.
Senaryo C: Hibrit (En gerçekçi saha yaklaşımı)
Akış:
- Ham veri landing’de tutulur (EL)
- Temel temizlik/standardizasyon yapılır (Silver)
- Raporlama için star schema + aggregation tablolar üretilir (Gold)
- Power BI gold katmandan beslenir
Ne zaman ideal?
Hem denetim istiyorsun hem esneklik. “İkisini birden” isteyen kurumların çoğu buraya düşer.
En Sık Yapılan Hatalar (Projenin Maliyetini Patlatır)
- “Ham veriyi direkt Power BI’a bağlayalım” (sonra model şişer, performans düşer)
- Her rapor için ayrı dönüşüm kuralı yazmak (tekil KPI’lar çoğalır, tutarsızlık artar)
- Star schema yerine “operasyonel şemayı rapora taşımak”
- Incremental yükleme stratejisi kurmamak (refresh süreleri uzar)
- Veri sözlüğü/KPI tanımlarını yazmadan ilerlemek (aynı KPI farklı hesaplanır)
Başlangıç İçin Pratik Checklist
Başlarken şu adımlarla ilerlemek çoğu projede işleri hızlandırır:
- “Gold katman” hedefini netleştir: Power BI neyi tüketecek?
- Boyut-fakt model taslağını çiz (star schema)
- Ham veriyi saklama ihtiyacını belirle (raw katman gerekli mi?)
- Incremental yükleme stratejisini baştan planla
- KPI sözlüğü hazırla (tanım, filtre, tarih mantığı)
- Power BI modunu belirle (Import/DirectQuery/Composite)
Sonuç: Doğru Seçim “ETL mi ELT mi” Değil, “Hangi Katmanda Ne Yapmalı?”
ETL ve ELT birbirinin düşmanı değil; doğru kurgulanınca birbirini tamamlayan iki yaklaşımdır. Power BI + SQL + Data Warehouse dünyasında sürdürülebilir başarı genelde şuradan gelir:
- Ham veri yönetimi (gerekliyse)
- Katmanlı dönüşüm disiplini (silver/gold)
- Raporlamaya özel, performans odaklı star schema
- Yenileme stratejisi (incremental)
- Tek bir “doğru KPI” kaynağı (governance)
Kısacası: Mimariyi iş ihtiyacına göre kurarsanız, ETL/ELT seçimi zaten “doğru yere” oturur.
Sıradaki Okumalar (İç Link Önerileri)
- Power BI Performans Optimizasyonu: Modelleme, Star Schema, Aggregation ve Hızlandırma Teknikleri
- SSIS ile ETL Tasarımı: Incremental Load, CDC ve Hata Yönetimi (Adım Adım)
- Veri Deposu Nedir? Kimball ile DWH Tasarımı: Fact, Dimension, SCD ve KPI Yönetimi
CTA (İletişim / Hizmet Metni)
Kurumunuz için ETL mi ELT mi daha doğru; bunu en net gösteren şey mevcut tablo hacimleri, kaynak sistem tipi ve Power BI kullanım şeklidir. İsterseniz mevcut yapınızı değerlendirip (1) hedef mimari, (2) katmanlı akış planı, (3) star schema taslağı ve (4) refresh/performans stratejisi içeren uygulanabilir bir yol haritası çıkarabiliriz.
Web Scraping Nedir?
Web Sitelerinden Veri Çıkarmanın Akıllı Yolu
Günümüzde internet, sayısız veriyle dolu dev bir bilgi kaynağıdır. Fiyatlar, ürün bilgileri, kullanıcı yorumları, haberler, istatistikler…
Ancak bu veriler çoğu zaman dağınık, manuel toplanması zor ve zaman alıcıdır.
İşte tam bu noktada Web Scraping devreye girer.
Web Scraping Nedir?
Web Scraping, web sitelerinde herkese açık olarak yayınlanan verilerin, yazılımlar aracılığıyla otomatik şekilde toplanması işlemidir.
Basitçe anlatmak gerekirse:
“Bir insanın web sitesine girip kopyala–yapıştır yapması yerine, bunu bir yazılımın saniyeler içinde ve hatasız yapmasıdır.”
Bu yöntem sayesinde yüzlerce hatta binlerce sayfadaki veriler kısa sürede analiz edilebilir hale gelir.
Web Scraping Ne İşe Yarar?
Web scraping yalnızca “veri çekmek” değildir; doğru karar almak için güçlü bir araçtır.
En Yaygın Kullanım Alanları

📊 Pazar ve Rakip Analizi
- Rakip fiyatlarının takibi
- Ürün karşılaştırmaları
- Kampanya ve indirim analizleri
🛒 E-Ticaret
- Ürün kataloglarının oluşturulması
- Fiyat değişimlerinin izlenmesi
- Stok ve ürün çeşitliliği analizi
🏠 Gayrimenkul & İlan Siteleri
- Bölgesel fiyat analizi
- Trend ve talep ölçümü
📰 Medya & İçerik Analizi
- Haber takibi
- Marka / kelime bazlı analizler
🤖 Veri Odaklı Karar Alma
- Raporlama
- Dashboard ve BI sistemleri
- Yapay zeka modelleri için veri besleme
Web Scraping Yasal mı?
Bu, en çok sorulan ve en önemli sorulardan biri.
Kısa cevap:
Evet, doğru yapıldığında yasaldır.
Dikkat edilmesi gerekenler:
- Sadece herkese açık (public) veriler alınmalıdır
- Kişisel veriler (KVKK / GDPR) korunmalıdır
- Site kullanım şartları (Terms of Service) dikkate alınmalıdır
- Sisteme zarar verecek yoğunlukta istek gönderilmemelidir
Profesyonel web scraping çözümleri etik, ölçekli ve kontrollü şekilde tasarlanır.
Web Scraping ile Manuel Veri Toplama Arasındaki Fark
| Manuel Toplama | Web Scraping |
| Zaman alıcı | Çok hızlı |
| İnsan hatasına açık | Otomatik & tutarlı |
| Ölçeklenemez | Binlerce sayfa |
| Güncel kalmaz | Sürekli güncellenir |
Neden Profesyonel Bir Çözüm Gerekir?

Birçok web sitesi:
- Bot korumaları
- CAPTCHA
- IP kısıtlamaları
- Dinamik (JavaScript) yapılar
kullanır.
Bu yüzden “basit bir script” çoğu zaman yeterli olmaz.
Sürdürülebilir, güvenli ve bakımı yapılabilir çözümler için profesyonel yaklaşım şarttır.
Biz Bu Konuda Nasıl Destek Oluyoruz?
Bir yazılım ve danışmanlık şirketi olarak:
- İhtiyaca özel web scraping çözümleri
- Ölçeklenebilir mimari
- Yasal ve etik çerçevede veri toplama
- Toplanan verilerin raporlanması ve analiz edilmesi
- Mevcut sistemlerle entegrasyon
konularında uçtan uca destek sağlıyoruz.
Sonuç
Web scraping, doğru kullanıldığında işletmelere rekabet avantajı, zaman tasarrufu ve veriye dayalı karar alma gücü kazandırır.
Eğer siz de:
- Manuel veri toplama ile vakit kaybediyorsanız
- Güncel ve güvenilir veriye ihtiyaç duyuyorsanız
- İşinizi veriyle büyütmek istiyorsanız
Web scraping çözümleri tam size göre olabilir.

Yazılım projeleri büyüdükçe kaliteyi sürdürülebilir şekilde yönetmek her geçen gün daha kritik hale geliyor. Hızlı release döngüleri, artan kullanıcı beklentileri ve karmaşık sistem mimarileri; yazılım test ve kalite süreçlerini yalnızca teknik bir gereklilik olmaktan çıkararak stratejik bir yatırım haline getiriyor.
Modern yazılım ekipleri artık test süreçlerini geliştirme sürecinin sonunda yapılan bir kontrol mekanizması olarak değil, tüm yaşam döngüsüne entegre edilmiş bir kalite yaklaşımı olarak ele alıyor.
Yazılım Test Süreçleri Nedir?
Yazılım test süreçleri; bir uygulamanın beklenen şekilde çalıştığını doğrulamak için planlanan ve uygulanan tüm kalite faaliyetlerini kapsar. Bu süreçler manuel testleri, otomasyon testlerini, performans testlerini ve sürekli entegrasyon kontrollerini içerir.
Doğru yapılandırılmış bir test süreci:
- Hataların erken aşamada yakalanmasını sağlar
- Geliştirme maliyetlerini azaltır
- Kullanıcı deneyimini iyileştirir
- Ekiplerin daha hızlı release yapmasına yardımcı olur
Modern Yazılım Geliştirmede Test Otomasyonu
Agile ve DevOps yaklaşımlarının yaygınlaşmasıyla birlikte test otomasyonu, yazılım projelerinde standart bir uygulama haline gelmiştir. Özellikle Playwright ve Selenium gibi araçlar sayesinde UI ve API testleri otomatik hale getirilebilir.
Test otomasyonunun temel avantajları:
- Regression test süreçlerini hızlandırır
- İnsan hatasını azaltır
- CI/CD pipeline içinde otomatik kalite kontrol sağlar
- Yazılım ekiplerine güvenli deploy imkanı sunar
Detaylı bilgi için: Test Otomasyonu Hizmetlerimiz
Performans Testleri Neden Göz Ardı Edilmemeli?
Bir yazılımın doğru çalışması kadar, yüksek kullanıcı yükü altında stabil kalması da kritik öneme sahiptir. Performans testleri sayesinde sistemin kapasitesi ölçülebilir ve potansiyel darboğazlar erken aşamada tespit edilebilir.
K6 ve JMeter gibi performans test araçları ile:
- Response time analizleri yapılır
- Sistem limitleri belirlenir
- API performansı ölçülür
- Grafana dashboard’ları ile metrikler görselleştirilir
Performans testleri özellikle büyüme hedefi olan ürünler için vazgeçilmezdir.
Test Piramidi Yaklaşımı Nedir?
Test piramidi; yazılım test stratejisini optimize etmek için kullanılan bir modeldir. Bu yaklaşımda:
- Alt katmanda unit ve API testleri
- Orta katmanda entegrasyon testleri
- Üst katmanda UI E2E testleri yer alır
Bu yapı sayesinde testler daha hızlı çalışır, bakım maliyeti düşer ve kalite sürdürülebilir hale gelir.
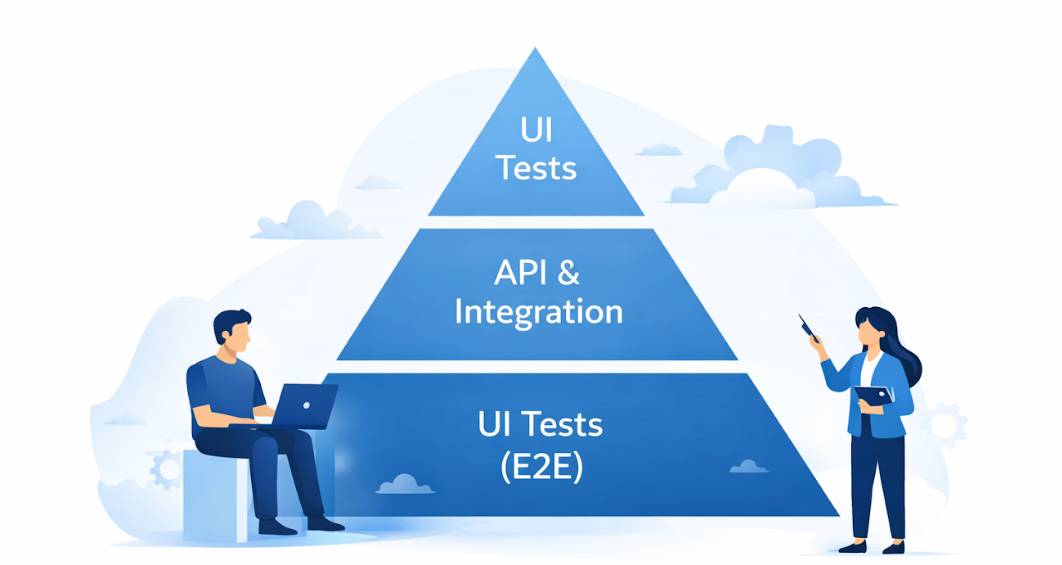
Yazılım Yaşam Döngüsünde Kalitenin Yeri
Modern QA yaklaşımında kalite yalnızca QA ekiplerinin sorumluluğu değildir. Ürün yöneticilerinden geliştiricilere kadar tüm ekipler kalite süreçlerinin bir parçası haline gelir.
Başarılı ekipler:
- Gereksinim aşamasında test senaryosu oluşturur
- Geliştirme sırasında otomasyon testleri yazar
- Release öncesi performans analizleri yapar
- Canlı ortam sonrası metrikleri izler
Bu yaklaşım “Shift-Left Testing” olarak adlandırılır ve modern yazılım ekiplerinin temel prensiplerinden biridir.
Kurumsal Projelerde QA Danışmanlığının Önemi
Birçok organizasyon, test süreçlerini güçlendirmek ve modern otomasyon altyapıları kurmak için QA danışmanlık hizmetlerinden yararlanmaktadır.
Profesyonel QA danışmanlığı sayesinde:
- Test süreçleri standart hale gelir
- Otomasyon mimarisi doğru kurgulanır
- Performans testleri sistematik şekilde uygulanır
- Ekiplerin teknik olgunluğu artar
Sonuç: Yazılım Kalitesi Bir Maliyet Değil, Yatırımdır
Yazılım test ve kalite süreçleri, modern dijital ürünlerin başarısını belirleyen en önemli unsurlardan biridir. Doğru strateji ile kurgulanan test süreçleri; ekiplerin daha hızlı hareket etmesini sağlarken kullanıcı güvenini de artırır.
Kaliteyi geliştirme sürecinin ayrılmaz bir parçası haline getiren organizasyonlar, rekabet avantajı elde eder ve uzun vadede daha sürdürülebilir ürünler ortaya çıkarır.
QA süreçlerinizi değerlendirmek için bizimle iletişime geçin

Kod Okunabilirliği, Temiz Kod Yazımı ve Yazılımın Uzun Vadeli Başarısı İçin İpuçları
Yazılım geliştirme dünyasında “temiz kod” kavramı sık sık duyduğumuz bir terim olsa da, çoğu zaman işin yoğunluğundan veya teslim tarihinin baskısından dolayı geri planda kalabiliyor. Ancak uzun vadede başarılı bir proje geliştirmek istiyorsak, kod okunabilirliği ve temiz kod yazımı olmazsa olmazdır.
Çünkü bugün hızlıca yazdığınız bir kod, yarın bakımını sizin ya da bir başkasının yapacağı devasa bir yapının parçası hâline gelir. Bu nedenle okunabilir, düzenli ve sürdürülebilir kod yazmak sadece bir tercih değil, yazılımın ömrünü uzatan önemli bir yatırımdır.
Kod Okunabilirliği Neden Bu Kadar Önemli?
Bir yazılım projesinin en büyük maliyet kalemlerinden biri geliştirme değil, bakımdır. Kodun anlaşılır olması, yeni özellik eklemekten hata düzeltmeye kadar pek çok süreci hızlandırır. Yazdığınız bir satır kodun üzerinden altı ay geçtiğinde, o kodu ilk defa görüyormuşsunuz gibi hissetmeniz oldukça normaldir. İşte tam bu noktada okunabilir kod devreye girer.
Okunabilir kod, amacını ilk bakışta anlatan koddur. Karmaşık ifadelerden mümkün olduğunca uzak durur. Değişken ve fonksiyon isimleri, kodun ne yaptığını açıklar nitelikte olmalıdır. Eğer bir fonksiyonun içini anlamak için başka dosyalara bakmanız gerekiyorsa, orada iyileştirme yapılması gereken bir durum var demektir.
Temiz Kod Yazmanın Temel Prensipleri
Temiz kod yazımı, sadece kurallara bağlı kalmak değil, aynı zamanda kodunuzu geleceğe hazırlamak demektir. Peki temiz kod için hangi prensipleri dikkate almak gerekiyor?
- Anlamlı İsimler Kullanın
Yazılım geliştiricilerin yaptığı en büyük hatalardan biri, zaman kazanmak için kısa veya belirsiz değişken isimleri kullanmaktır. Oysa isimlendirme kodun okunabilirliğinin yarısıdır.
x, y, temp gibi değişkenler yerine productPrice, userEmail, orderList gibi isimler daha açıklayıcıdır.
- Fonksiyonları Küçük Tutun
Bir fonksiyon ne kadar küçükse, o kadar okunabilir ve test edilebilirdir. Uzayan fonksiyonlar genellikle birden fazla iş yapar ve bu da kod karmaşasına yol açar. Her fonksiyon tek bir iş yapsın ve onu iyi yapsın.
- Gereksiz Kodlardan Kurtulun
Kullanılmayan değişkenler, artık çalışmayan fonksiyonlar veya eskiden kalmış yorum satırları kodu kirletir. Gereksiz her satır, bugüne değilse bile yarın bir sorun çıkarma potansiyeli taşır. Bu yüzden kodu temiz tutmak uzun vadeli başarı için çok önemlidir.
- Kod Tekrarından Kaçının
DRY (Don’t Repeat Yourself) prensibi yazılım dünyasının altın kurallarındandır. Aynı kodu birden fazla yerde yazmak, hem bakım maliyetini artırır hem de hata riskini yükseltir. Ortak kod bloklarını fonksiyon hâline getirerek tekrar kullanılabilir yapabilirsiniz.

- Yorum Satırlarını Doğru Kullanın
İyi yazılmış bir kod genellikle fazla yoruma ihtiyaç duymaz. Ancak bazen algoritma karmaşık olabilir veya özel bir sebep nedeniyle belirli bir işlem yapılabilir. Bu gibi durumlarda kısa ve net yorumlar büyük fayda sağlar. Önemli olan yorumun kodu açıklaması, kodun yerine geçmesi değildir.
Arca Yazılım olarak; profesyonel yazılım ekiplerimizle, projelerimizde temiz kod standartlarına titizlikle uyarak sürdürülebilir, kolay geliştirilebilir ve kaliteli yazılım mimarilerinin ortaya çıkmasını sağlıyoruz.
Bu yaklaşım, hem mevcut projelerin sağlıklı ilerlemesini hem de uzun vadeli büyümeyi destekler.
Yazılımın Uzun Vadeli Başarısı İçin İpuçları
Temiz kod yazmak sadece bugünü kurtarmaz, projenin geleceğini de şekillendirir. İşte yazılım projelerinin uzun ömürlü olmasını sağlayan bazı ipuçları:
- Standardize Edilmiş Bir Kod Yapısı Kullanın
Ekibinizle birlikte bir kod standardı belirlemek, projenin tüm parçalarının uyum içinde çalışmasını sağlar. Aynı projede herkesin farklı tarzda kod yazması, zamanla kaosa neden olabilir.
- Düzenli Kod İncelemeleri Yapın
Kod incelemeleri (code review), hem kod kalitesini artırır hem de ekip içi bilgi paylaşımını güçlendirir. Bir başkasının kodunu incelemek, kendi kodunuzda fark etmediğiniz hataları görmenizi sağlar.
- Test Yazmayı İhmal Etmeyin
Testler, yazılımın uzun vadeli başarısının en kritik parçalarından biridir. Bir fonksiyonda yapılan küçük bir değişiklik, sistemin başka bir noktasını bozabilir. Testler bu tür durumların önüne geçer ve güvenli geliştirme sağlar.
- Basit Tutun
Karmaşık çözüm her zaman iyi çözüm değildir. Çoğu zaman en basit yaklaşım hem okunabilirlik hem sürdürülebilirlik açısından daha değerlidir. Fazla mimari katman veya gereksiz tasarım kararları gelecekte işinizi zorlaştırabilir.
- Sürekli Refactoring Yapın
Refactoring, mevcut kodu iyileştirme sürecidir. Kod çalışıyor diye dokunmamak, uzun vadede teknik borcun artmasına neden olur. Küçük ama düzenli iyileştirmeler projeyi sağlıklı tutar.

Kod okunabilirliği ve temiz kod yazımı, yazılım geliştirme sürecinde genellikle göz ardı edilen fakat uzun vadede en çok fayda sağlayan unsurlardan biridir. Temiz bir kod tabanı, hem geliştirme hızını artırır hem de ekip içindeki iletişimi kolaylaştırır. Ayrıca projenin ömrünü uzatır ve teknik borçla boğuşmanızı engeller. Eğer uzun vadeli bir başarı hedefliyorsanız, temiz kodu bir seçenek olarak değil, bir zorunluluk olarak görmekte fayda var.
Yazılım projelerinizin doğru temeller üzerine inşa edildiğinden emin olmak istiyorsanız, profesyonel bir bakış açısıyla sürecinizi değerlendirmek her zaman büyük avantaj sağlar. Projelerimiz hakkında detaylı bilgi almak ya da teknik danışmanlık hizmetlerinden faydalanmak için [email protected]
adresi üzerinden Arca Yazılım ekibiyle iletişime geçebilirsiniz.
Arca Yazılım’ın sunduğu tüm hizmetler ve etkileyici referansları hakkında daha fazla bilgi almak için resmi web sitesini ziyaret edebilirsiniz: www.arcayazilim.com

Yapay Zeka, Derin Öğrenme ve Görüntü İşlemede Başarının Anahtarı: Mükemmel Veri Hazırlama Prensipleri
Yapay Zeka (YZ) çağı, hayatımızın her alanını dönüştüren, daha akıllı, daha hızlı ve daha verimli sistemlerin önünü açan devasa bir teknolojik dalgadır. Akıllı telefonlarımızdaki anlık çevirilerden, otonom araçların karmaşık yol kararlarına, hatta hastalıklı hücrelerin mikroskobik düzeyde tespitine kadar, YZ uygulamaları inanılmaz bir hızla gelişmekte ve olgunlaşmaktadır. Derin Öğrenme (Deep Learning), özellikle verilerin artmasıyla hızlı bir ivme ile gelişmeye başlamıştır. Bu güçlü algoritmanın en popüler ve etkileyici uygulama alanlarından biri Görüntü İşlemedir. Ancak bu teknolojilerin potansiyelini tam olarak ortaya çıkarmanın kritik bir sırrı vardır: Titizlikle Uygulanan Veri Hazırlama Prensipleri.
✨ Yapay Zeka ve Derin Öğrenmenin Derinlikleri
Yapay Zeka, en geniş tanımıyla, makinelerin tıpkı bir insan gibi öğrenmesini, akıl yürütmesini, problem çözmesini ve nihayetinde özerk kararlar vermesini sağlayan bilim dalıdır. YZ’nin altında, makinelerin büyük miktarda veriden örüntüleri ve ilişkileri öğrenmesini sağlayan Makine Öğrenimi (Machine Learning) bulunur.
Derin Öğrenme ise, Makine Öğreniminin bir alt kümesi olup, insan beyninin biyolojik sinir ağlarından ilham alan Çok Katmanlı Yapay Sinir Ağları (Deep Neural Networks) kullanır. Bu ağlar, bir girdiyi (örneğin bir fotoğrafı) alıp, bilgiyi arka arkaya sıralanmış gizli katmanlar aracılığıyla işler ve bir çıktı (örneğin fotoğraftaki nesnenin etiketi) üretir. Bu “derin” yapı, geleneksel yöntemlerin aksine, verilerdeki karmaşık ve soyut desenleri, katmanlar arasında derinlemesine bir hiyerarşi kurarak otomatik olarak öğrenme yeteneği kazandırır.
💡 Derin Öğrenmenin Farkı: Geleneksel Makine Öğrenimi yöntemlerinde, verilerin anlamlı özelliklerinin (feature engineering) bir uzman tarafından belirlenmesi ve elle çıkarılması gerekirken, Derin Öğrenme modelleri, (özellikle Evrişimli Sinir Ağları – CNN gibi mimariler), bu özellikleri kendi başlarına, ham veriden doğrudan öğrenebilirler. Bu özellik, Derin Öğrenmeyi büyük veri ve karmaşık görevler için vazgeçilmez kılmıştır.
🖼️ Görüntü İşlemede Derin Öğrenme ile Sınırları Aşmak
Görüntü İşleme (Image Processing), sayısal görüntüleri analiz etme, değiştirme ve onlardan yüksek düzeyde anlamlı bilgiler çıkarma sürecidir. Derin Öğrenme, Görüntü İşlemeyi eski kurallara dayalı sistemlerden ayırarak bir devrim yarattı. Günümüzde, Evrişimli Sinir Ağları (CNN) temelli Derin Öğrenme modelleri;
- Nesne Tanıma ve Tespiti: Bir görüntüdeki farklı nesnelerin ne olduğunu, nerede bulunduğunu ve hangi sınıfa ait olduğunu belirleme (örneğin, trafikteki araçları, yayaları ve bisikletlileri anlık olarak tespit etme).
- Görüntü Sınıflandırma: Bir görüntünün bütünüyle hangi kategoriye ait olduğunu belirleme (örneğin, bir tıbbi MR görüntüsünün tümör içerip içermediğini sınıflandırma).
- Semantik Segmentasyon: Görüntüdeki her bir pikseli ait olduğu nesne sınıfına göre etiketleme ve hassas sınırlarını belirleme (örneğin, coğrafi görüntülerde su, orman ve yerleşim alanlarını pikseller düzeyinde ayırma).
gibi görevlerde insan algılama ve analiz performansını aşan doğruluk seviyelerine ulaşabilmektedir. Bu üstün performansı mümkün kılan tek bir faktör vardır: Büyük, Yüksek Kaliteli ve İyi Hazırlanmış Veri Setleri.
🔑 Başarının Altın Kuralı: Veri Hazırlama Prensipleri
Derin Öğrenme modelleri, eğitildikleri veri setinin kalitesi ve çeşitliliği kadar başarılıdır. Eğer model “çöp” verilerle eğitilirse, çıktısı da “çöp” olacaktır (“Garbage In, Garbage Out” prensibi). Veri Hazırlama, ham ve düzensiz veriyi alıp, modelin etkili bir şekilde öğrenebileceği ve gerçek dünya problemlerine genelleme yapabileceği bir forma dönüştürme sürecidir. Bu süreç, genellikle bir yapay zeka projesinin %60 ila %80’ini kapsar ve başarının en kritik aşamasıdır.
İşte Görüntü İşleme projelerinde mükemmeliyet için izlenmesi gereken temel Veri Hazırlama Prensipleri:
- Veri Toplama, Çeşitlilik ve Dengeleme (The Foundation)
Bir Derin Öğrenme modelinin sağlam bir temel üzerine inşa edilmesi, veri toplama aşamasıyla başlar:
- Alaka Düzeyi ve Kapsamlılık: Toplanan verinin, çözülmek istenen problemi gerçek dünyadaki tüm olası senaryolarıyla temsil etmesi gerekir. Bir güvenlik kamerası modelini eğitirken sadece güneşli gün ışığı görüntüleri kullanmak, modelin gece veya sisli hava koşullarında tamamen başarısız olmasına yol açacaktır. Veri setinde tüm aydınlatma, hava ve açı koşulları kapsanmalıdır.
- Sınıf Dengesizliğinin Giderilmesi: Veri setindeki farklı sınıfların örnek sayıları arasında büyük farklar olması (Sınıf Dengesizliği), modelin eğitim sırasında sayıca fazla olan sınıfa ağırlık vermesine ve sayıca az olan, ancak kritik olabilecek sınıfları (örneğin tıbbi anormallikler) görmezden gelmesine yol açar. Bu durum, alt örnekleme (undersampling), üst örnekleme (oversampling) veya sentetik veri oluşturma (SMOTE gibi) teknikleriyle dengelenmelidir.
- Veri Ön İşleme ve Normalizasyon (The Clean-up)
Ham görüntülerin işlenmeye hazır hale getirilmesi, öğrenme sürecinin verimini artırır:
- Gürültü ve Bozulma Temizliği: Düşük çözünürlüklü, bulanık, aşırı pozlanmış veya sensör hatası içeren görüntüler modelin ayırt etme yeteneğini köreltir. Bu veriler temizlenmeli veya iyileştirme algoritmaları ile düzeltilmelidir.
- Yeniden Boyutlandırma ve Standardizasyon: Birçok model sabit bir girdi boyutuna ihtiyaç duyar (örneğin 224 x 224 piksel). Tüm görüntüler bu boyuta ölçeklenmeli ve aynı zamanda piksel değerleri Normalizasyon (genellikle 0 ile 1 arasına veya –1 ile 1 arasına getirilmesi) ve Standardizasyon (ortalama ve standart sapma kullanılarak) işlemlerinden geçirilmelidir. Bu, modelin eğitimini daha kararlı hale getirir ve yakınsama süresini kısaltır.
- Etiketleme ve Açıklama Kalitesi (The Truth)
Veri etiketleme, modelin “gerçeği” öğrendiği yerdir. Buradaki en ufak bir hata bile tüm modeli bozabilir:
- Kesinlik (Precision) ve Tutarlılık: Görüntüdeki nesnelerin ve kategorilerin etiketlenmesi kesin, doğru ve tüm veri kümesi boyunca tutarlı olmalıdır. Görüntü İşlemede bu, Sınırlayıcı Kutu (Bounding Box), Poligon çizimi veya piksel düzeyinde hassas Segmentasyon Maskeleri ile yapılır. Örneğin, bir nesnenin sınırının bir etiketleyicide 5 piksel içeriden, diğerinde ise 5 piksel dışarıdan çizilmesi, modelin kafa karışıklığına neden olur.
- Etiketleme Standartları: Etiketleyiciler arasında standartlaştırılmış, açık ve net bir etiketleme kılavuzu oluşturulması, etiketleme kalitesinin yüksek tutulması için şarttır. Kalite kontrol mekanizmaları, etiketleme hatalarının hızla tespit edilip düzeltilmesini sağlamalıdır.
- Veri Artırma (Data Augmentation) (The Growth Hack)
Küçük bir veri setinden maksimum verimi almanın ve modelin genelleme yeteneğini artırmanın en etkili yolu Veri Artırmadır. Bu, mevcut görüntülere anlamsal içeriğini değiştirmeyen rastgele dönüşümler uygulamaktır:
- Geometrik Dönüşümler: Görüntüyü rastgele açılarla çevirme (rotation), yatay veya dikey aynalama (flipping), kaydırma (shifting) ve rastgele kırpma (cropping).
- Fotometrik Dönüşümler: Parlaklık, kontrast, renk doygunluğu ve keskinlik değerlerinde rastgele değişiklikler yapılması.
Bu teknikler, modelin eğitim verilerinde görmediği, ancak gerçek dünyada karşılaşabileceği ufak değişikliklere karşı daha sağlam (robust) olmasını sağlar ve aşırı öğrenmeyi (overfitting) önler.
🚀 Sektörel Uygulamalar ve Profesyonel Yaklaşım
Yapay Zeka, Derin Öğrenme ve Görüntü İşleme teknolojileri, endüstriyel kalite kontrolünden (hata tespiti), sağlık hizmetlerinde (radyoloji analizi) hızlı ve doğru teşhise, perakendede (raf analizi) ve güvenlikte (yüz tanıma) kadar her alanda yeni verimlilik kapıları açmaktadır. Bu karmaşık ve yüksek riskli projelerde, özellikle Veri Hazırlama süreçlerinin titizlikle ve profesyonelce yönetilmesi, projenin sadece başarılı değil, aynı zamanda etik ve güvenilir olmasını da sağlar.
Bu kritik alanda güvenilir, tecrübeli ve uzman bir iş ortağı arıyorsanız, Arca Yazılım‘ın sunduğu ileri teknoloji çözümler ve uzmanlık, projelerinizi sağlam bir temele oturtmak ve bir adım öteye taşımak için en doğru adrestir. Kaliteli yazılım geliştirme metodolojileri, özelleştirilmiş Derin Öğrenme model mimarileri ve yüksek standartlardaki Veri Hazırlama süreçleri ile Arca Yazılım, dijital dönüşüm yolculuğunuzda en büyük destekçiniz olacaktır.
Veri setinizin yapay zeka için doğru temeli oluşturduğundan emin olmak, projeleriniz hakkında detaylı bilgi almak ve teknik danışmanlık hizmetlerinden faydalanmak için [email protected] e-posta adresi üzerinden Arca Yazılım ekibiyle iletişime geçebilirsiniz. Arca Yazılım’ın sunduğu tüm hizmetler ve etkileyici referansları hakkında daha fazla bilgi almak için lütfen resmi web sitesi olan www.arcayazilim.com adresini ziyaret ediniz.

Yapay zeka (YZ), artık niş bir teknoloji olmaktan çıkıp yazılım geliştirmenin temel bir bileşeni haline geldi. Kullanıcı deneyimini kökten değiştiren, verimliliği artıran ve daha önce imkansız görülen işlevleri mümkün kılan akıllı uygulamalar, pazarın yeni standardını oluşturuyor.
OpenAI ChatGPT, Google Gemini ve DeepSeek gibi güçlü dil modellerinin (LLM) sunduğu API’lar (Uygulama Programlama Arayüzleri), bu teknolojilerin standartlaştırılmasında önemli rol oynamakta.
Ancak, bu güçlü araçları mevcut veya yeni projelere entegre etmek, sadece bir API anahtarı alıp kullanmaktan çok daha fazlasını gerektirir. Başarılı bir yapay zeka entegrasyonu, doğru mimari kararları, maliyet yönetimi, performans optimizasyonu ve modelin yeteneklerini derinlemesine anlamayı zorunlu kılar.
Bu teknik makalede, üç dev modelin API’larını kullanarak akıllı uygulama geliştirme sürecinin teknik derinliklerine ineceğiz. Hangi API’ın projeniz için daha uygun olduğunu, entegrasyon sırasında karşılaşılacak mimari zorlukları ve bu zorlukların üstesinden gelmek için gereken en iyi pratikleri ele alacağız.
🛠️ API Entegrasyonunun Teknik Temelleri
Hangi modeli seçerseniz seçin, temel API etkileşim mekaniği benzerdir. Bu süreç, temelde istemci (sizin uygulamanız) ile sunucu (YZ modelinin barındırıldığı yer) arasında gerçekleşen güvenli bir HTTP iletişimine dayanır.
- Kimlik Doğrulama (Authentication)
Tüm büyük sağlayıcılar, API’larına erişimi korumak için API anahtarları kullanır. Bu anahtar, genellikle Authorization başlığında (Header) bir Bearer token olarak gönderilir. Bu anahtarların sunucu tarafında güvenli bir şekilde saklanması (örneğin, ortam değişkenleri veya gizli yönetim servisleri aracılığıyla) önemlidir.
İstemci tarafına (mobil uygulama veya web tarayıcısı) doğrudan API anahtarı gömmek, ciddi güvenlik zafiyetlerine yol açar.
- SDK vs. Ham HTTP İstekleri
- SDK (Software Development Kit): OpenAI (Python, Node.js), Google (Vertex AI/Gemini SDK’ları) ve DeepSeek, API etkileşimlerini soyutlayan resmi veya topluluk destekli kütüphaneler sunar. SDK kullanmak, kimlik doğrulama, hata yönetimi ve karmaşık veri yapılarının (örneğin, Gemini’nin multimodal içerik blokları) yönetimini basitleştirir.
- Ham HTTP İstekleri: curl, fetch veya HttpClient gibi standart kütüphanelerle doğrudan API endpoint’lerine (örn. https://api.openai.com/v1/chat/completions) istek atabilirsiniz. Bu yaklaşım, tam kontrol sağlar ancak yeniden deneme (retry) mekanizmaları ve hata ayrıştırma gibi işlemleri manuel olarak yönetmenizi gerektirir.
- Temel Veri Yapısı: İstek (Request) ve Yanıt (Response)
Çoğu modern LLM API’ı, JSON formatında veri alışverişi yapar. Tipik bir “chat completion” (sohbet tamamlama) isteği şu bileşenleri içerir:
- Model: Kullanmak istediğiniz modelin kimliği (örn. gpt-4o, gemini-1.5-pro, deepseek-chat).
- Messages (Mesajlar): Konuşma geçmişi. Bu, API’ların “durumsuz” (stateless) olmasından kaynaklanır. Modelin önceki konuşmaları hatırlaması için tüm geçmişi her istekte göndermeniz gerekir. Bu “messages” dizisi genellikle role (system, user, assistant) ve content içeren objelerden oluşur.
- Parametreler: temperature (rastgelelik), max_tokens (maksimum yanıt uzunluğu), stream (yanıtı akış olarak alma) gibi ayarlar.
Yanıt (Response) ise genellikle modelin cevabını (content) ve kullanım meta verilerini (harcanan token sayısı vb.) içeren bir JSON objesidir.
⚖️ Yaygın Güçlü Dil Modelleri Uygulamaları
Her API’ın kendine özgü güçlü yanları ve teknik nüansları vardır. Doğru seçimi yapmak, projenizin gereksinimlerine bağlıdır.
OpenAI (ChatGPT): Olgun Ekosistem ve Gelişmiş Araçlar
OpenAI’ın API’ı, pazarın fiili standardı haline gelmiştir.
- Teknik Güç: Özellikle gpt-4o ile sunulan hız, zeka ve kararlılık kombinasyonu.
- Fonksiyon Çağırma (Function Calling / Tools): Bu, OpenAI API’nin en güçlü teknik özelliklerinden biridir. Modele, “hava durumunu al” veya “veritabanından kullanıcıyı getir” gibi özel fonksiyonları tanımlamanıza olanak tanır.
- Model, bir kullanıcı isteğini bu fonksiyonlardan birine yönlendirmesi gerektiğini anladığında, çağırmanız gereken fonksiyon adını ve argümanları içeren bir JSON yanıtı döner. Bu, YZ’yi harici sistemlere ve araçlara bağlamak için yararlanılabilecek bir özelliktir.
- Ekosistem: Geniş dokümantasyon, büyük topluluk desteği ve LangChain, LlamaIndex gibi framework’lerle derin entegrasyon.
Google (Gemini): Doğal Multimodalite ve Ekosistem Entegrasyonu
Google Gemini, “doğuştan” multimodal (çoklu modalite) bir model olarak tasarlanmıştır.
- Teknik Güç: Gemini, metin, görüntü, ses ve videoyu tek bir istek içinde doğal olarak işleyebilir. ChatGPT’nin aksine (görüntüleri ayrı bir girdi olarak ele alır), Gemini farklı modaliteler arasındaki karmaşık ilişkileri anlayabilir. Örneğin, bir video ve bir metin sorgusunu aynı anda analiz edebilir.
- API Yapısı: Gemini API (Vertex AI veya Google AI Studio üzerinden), GenerativeModel sınıfını temel alır. İstekler, Content objeleri içinde Part (parça) olarak gönderilir. Bir Part metin, diğer bir Part base64 kodlu bir görüntü olabilir.
- Ekosistem: Google Cloud Platform (GCP) ve Vertex AI ile tam entegrasyon, kurumsal düzeyde ölçeklendirme, güvenlik ve veri yönetimi (RAG için Vertex AI Search vb.) sunar.
DeepSeek: Kod Uzmanlığı ve Maliyet Verimliliği
DeepSeek, özellikle kodlama ve teknik görevler için optimize edilmiş bir model olarak öne çıkar.
- Teknik Güç: deepseek-coder modelleri, kod tamamlama, kod çevirisi ve teknik problem çözme konularında olağanüstü performans gösterir.
- API Yapısı: DeepSeek API, teknik bir avantaj olarak OpenAI API standardıyla yüksek uyumluluk sunar. Bu, gpt-3.5-turbo için yazdığınız bir entegrasyonun, API endpoint’ini ve anahtarını değiştirerek çok az değişiklikle veya sıfır değişiklikle DeepSeek’e taşınabileceği anlamına gelir. Bu, maliyet optimizasyonu için farklı modeller arasında geçiş yapmayı kolaylaştırır.
- Maliyet: Genellikle OpenAI’ın üst düzey modellerinden daha uygun maliyetli bir alternatif sunarak, yüksek hacimli işlemler için cazip bir seçenek oluşturur.
🏗️ Akıllı Uygulama Mimarisi: API Çağrısının Ötesi
Bir YZ API’sini entegre etmek, sadece bir HTTP isteği göndermek değildir. Uygulamanızın bu isteği nasıl yönettiği, yanıtı nasıl işlediği ve kullanıcıya nasıl sunduğu da önem taşımaktadır.
Durum Yönetimi (State Management) ve Konuşma Hafızası
Yukarıda belirtildiği gibi, LLM API’ları stateless (durumsuz)’dur. Bir kullanıcının “Az önce ne sormuştum?” demesi model için anlamsızdır. Bu nedenle, konuşma geçmişini (chat history) sizin yönetmeniz gerekir.
- Kısa Vadeli Hafıza: Kullanıcının mevcut oturumdaki konuşmasını bir dizi (array) olarak uygulamanızın hafızasında tutar ve her yeni istekte bu diziyi API’ye gönderirsiniz.
- Uzun Vadeli Hafıza: Konuşma geçmişini bir veritabanında (örn. Redis, PostgreSQL, MongoDB) saklamak, kullanıcının oturumu kapatsa bile geri dönüp devam edebilmesini sağlar. Bu, token maliyetlerini yönetmek için “özetleme” (summarization) teknikleri gerektirebilir.
Asenkron İşlemler ve Yanıt Akışı (Streaming)
Bir LLM’den yanıt almak (özellikle karmaşık sorgularda) saniyeler sürebilir. Kullanıcıya boş bir yükleme ekranı göstermek kötü bir kullanıcı deneyimidir (UX).
- Asenkron İstekler: Rapor oluşturma veya e-posta taslağı hazırlama gibi uzun süren görevler için API isteğini bir arka plan iş kuyruğuna (örn. RabbitMQ, Kafka, Celery) göndermek gerekir. İşlem bittiğinde kullanıcıya bildirim gönderilir.
- Streaming (Akış): Sohbet robotları (chatbot) için en iyi pratiktir. API’ye stream: true parametresi gönderildiğinde, model yanıtı tek bir blok halinde değil, kelime kelime (veya token token) gönderir. Bu, sunucu tarafında Server-Sent Events (SSE) veya WebSockets kullanılarak istemciye aktarılır ve kullanıcı, yanıtı tıpkı bir insanın yazıyormuş gibi anlık olarak görür.
📈 Entegrasyon Zorlukları ve Çözüm Önerileri
- Maliyet Yönetimi: Token, YZ API’larının para birimidir. Hem girdi (prompt) hem de çıktı (response) token’ları ücretlendirilir. Konuşma geçmişinin çok uzaması maliyetleri hızla artırabilir. Çözüm olarak; konuşma geçmişini özetleme, max_tokens sınırlaması getirme ve kullanıcı bazlı kotalar uygulama gibi stratejiler geliştirilmelidir.
- Rate Limiting (Hız Sınırları): Tüm API sağlayıcıları, saniye veya dakika başına istek limitleri (rate limits) uygular. Uygulamanızın bu limitleri aşması 429 Too Many Requests hatalarına yol açar. Bu durumu yönetmek için “exponential backoff” (üstel geri çekilme) algoritmaları ve yerel bir önbellekleme (caching) mekanizması kurulmalıdır.
- Veri Gizliliği ve Güvenlik: API’ye gönderilen verilerin (özellikle OpenAI) model eğitimi için kullanılıp kullanılmayacağı önemli bir konudur. Kurumsal entegrasyonlarda, API sağlayıcısının veri gizliliği sözleşmelerini (Data Processing Agreements) dikkatle incelemek veya verilerin eğitim için kullanılmamasını (opt-out) seçmek gerekir. Hassas kişisel veriler (PII) gönderilmeden önce maskelenmelidir.
Basit bir chatbot’tan, kendi kurumsal verilerinizle konuşan karmaşık analiz araçlarına kadar, yapay zekanın potansiyelinden tam olarak yararlanmak, iyi bir teknolojik altyapı gerektirmektedir.
Arca Yazılım, modern yapay zeka modellerini kullanarak işletmenize özel, ölçeklenebilir ve güvenli akıllı uygulamalar geliştirme konusunda tecrübelenmiş bir şirkettir. İster mevcut sistemlerinize YZ zekası katmak, ister sıfırda bir proje geliştirmek isteyin, deneyimli mühendis kadromuzla vizyonunuzu gerçeğe dönüştürmeye hazırız.
Projelerinizi bir sonraki seviyeye taşımak ve yapay zeka entegrasyonunun karmaşıklığını bir uzmana bırakmak için Arca Yazılım ekibiyle iletişime geçin.
Daha fazla bilgi için www.arcayazilim.com adresini ziyaret edebilir veya proje detaylarınızı görüşmek üzere [email protected] üzerinden doğrudan sorularınızı iletebilirsiniz.

Dijital Randevu Sistemlerinin İşletmeler İçin Artan Önemi
Dijitalleşme süreçleri hızlandıkça işletmelerin müşteriye ulaşma ve hizmet sunma biçimleri de köklü şekilde değişmektedir. Özellikle hizmet temelli sektörlerde randevu veya rezervasyon kavramı artık sadece telefonla yapılan bir işlem olmaktan çıkmış, tamamen yazılımlar üzerinden yönetilen profesyonel bir sürece dönüşmüştür.
Yoğun müşteri akışına sahip işletmelerde manuel randevu kaydı tutmak hem zaman kaybına yol açar hem de hatalara neden olur. Bunun yerine dijital rezervasyon sistemleri kullanmak işletmeye hız, güven ve verim kazandırır. Müşteriler istedikleri zaman çevrimiçi olarak randevu oluşturabildiği için işletmeye ulaşma süreci kolaylaşır.
Aynı zamanda işletme, yoğunluğunu tek panelden takip ettiği için gün içinde oluşabilecek karışıklıkların önüne geçilmiş olur. Bu durum hem çalışan düzeni hem müşteri memnuniyeti açısından güçlü bir avantajdır. Dijital sistemler, randevu kayıtlarını saklama ve arşivleme konusunda da daha güvenlidir çünkü tüm bilgiler merkezi bir veritabanında toplanır.
Yeni nesil rezervasyon yazılımlarının en önemli katkılarından biri hızdır. Müşteri, saniyeler içinde boş bir saat bulabilir ve işlem tamamlanır. İşletmenin çalışma saatleri, müsaitlik durumu ve hizmet içerikleri sistemde açık şekilde sunulduğu için bilgi karmaşası ortadan kalkar. Ayrıca sürekli gelişen yazılım teknolojileri sayesinde bu sistemler artık masaüstünün dışında mobil cihazlarda da kusursuz çalışır hale gelmiştir. Bu da müşterilere her an işlem yapabilme özgürlüğü sağlar.
İşletmeler için dijital rezervasyon sistemleri sadece bir teknolojik yenilik değil, bir zorunluluk haline gelmiştir. Çünkü modern kullanıcılar hızlı ve erişilebilir hizmet beklemektedir. Bu beklentiyi karşılamayan işletmeler rakiplerine göre geride kalmakta, dijital randevu sunan işletmeler ise daha profesyonel bir imaj oluşturmaktadır.
Rezervasyon Sistemlerinin İşletmelere Sağladığı Temel Avantajlar
Dijital randevu yönetimi işletmelere birçok açıdan fayda sağlar. Bunların başında zaman yönetimi gelir. Randevu programını anlık olarak görmek çalışanların iş yükünü planlamasını kolaylaştırır. Yoğun saatlerde kapasite ayarlaması yapılabilir, boş zamanlar daha verimli değerlendirilebilir. Bu sistemler sayesinde randevu çakışmaları neredeyse tamamen tarih olur. Bir diğer önemli avantaj müşteri bilgilerinin düzenli tutulmasıdır. Rezervasyon sistemi müşterilerin iletişim bilgilerini, hizmet geçmişlerini ve ödeme detaylarını tek yerde toplar. Bu bilgiler hem işlem hızını artırır hem de müşteri ile daha güçlü bir bağ kurulmasına yardımcı olur. Örneğin müşterinin daha önce aldığı hizmete göre yeni bir hizmet önerisi yapılabilir veya uygun kampanyalar sunulabilir.
Dijital sistemlerin sağladığı otomatik hatırlatma özelliği ise gelir kaybını azaltmak açısından kritik bir rol oynar. Randevularını unutan müşteriler işletmede boşluklar oluşturabilir. Sistem tarafından gönderilen SMS, e-posta veya WhatsApp hatırlatmaları sayesinde bu oran oldukça düşer. Bu da hem daha planlı bir iş düzeni hem de daha yüksek gelir anlamına gelir. Ayrıca rezervasyon sistemleri işletme verimliliğini ölçmek için kullanılabilir. Günlük veya haftalık yoğunluk raporları, en çok tercih edilen hizmetler ve çalışan performansı gibi veriler işletmeye önemli bir içgörü sağlar.
Bu bilgiler sayesinde fiyatlandırma politikası düzenlenebilir, çalışma saatleri optimize edilebilir ve geliştirilmesi gereken noktalar kolayca tespit edilebilir.
Müşteri Yönetimi ile Rezervasyon Sistemlerinin Bütünleşmesi
Rezervasyon yazılımları, müşteri yönetimi araçları ile birleştiğinde işletmelerin çok daha profesyonel bir hizmet sistemi kurmasını sağlar. Müşteri ilişkileri yönetimi sayesinde her müşterinin geçmişi detaylı şekilde takip edilir. Ne kadar sıklıkla geldiği, hangi hizmetlerden yararlandığı ve hangi personeli tercih ettiği gibi bilgiler işletmenin daha kişisel bir deneyim sunmasına olanak tanır.
Bu bilgiler işletmenin pazarlama aktivitelerini de geliştirir. Örneğin sık gelen müşterilere özel indirimler, doğum günü mesajları veya hizmet önerileri gönderilebilir. Bu tür kişiselleştirilmiş iletişim yöntemleri müşteri sadakatini artırır. Müşterinin kendisini özel hissetmesi, sadece memnuniyeti değil aynı zamanda tekrar satın alma oranını da yükseltir.
Rezervasyon sistemlerinde bulunan otomatik bildirim özellikleri de müşteri yönetiminin önemli bir parçasıdır. İşletme çalışma saati değişiklikleri, yeni kampanya duyuruları veya hizmet güncellemelerini müşterilere hızlıca iletebilir. Bu tür düzenli iletişim alışkanlığı olan işletmeler daha profesyonel bir algı oluşturur. Müşteri yönetimi ve rezervasyon sistemi birlikteliği işletmenin hizmet kalitesini hem görünür hem de ölçülebilir hale getirir. Verilere dayalı karar almak günümüz işletmeciliğinin temel gerekliliklerinden biridir ve bu sistemler tam olarak bu ihtiyacı karşılar.
Farklı Sektörlerde Rezervasyon Sistemlerinin Kullanımı
Dijital randevu ve rezervasyon sistemlerinin kullanım alanı oldukça geniştir ve hemen her sektör için uyarlanabilir.
Sağlık ve Klinik Hizmetleri
Sağlık sektörü randevu sistemlerine en çok ihtiyaç duyan alanlardan biridir. Hastalar doktor seçebilir, uygun saatleri görebilir ve muayene sürecini kolayca planlayabilir. Bekleme süresinin azalması hem doktorlar hem de hastalar açısından daha iyi bir deneyim sağlar.
Güzellik ve Kişisel Bakım Merkezleri
Güzellik salonları, kuaförler ve estetik merkezleri için rezervasyon sistemi neredeyse zorunludur. Personel programı, oda takvimi ve hizmet süresi gibi birçok değişken sistem üzerinden kontrol edilir. Yoğun saatlerde düzen sağlamak bu yazılımlar sayesinde çok daha kolay hale gelir.
Araç Servisleri ve Teknik Hizmetler
Oto servisleri ve teknik destek firmaları araç kabul işlemlerinde randevu sistemi kullanarak bekleme sürelerini azaltır. Müşteri planlı şekilde geldiği için operasyon alanında karışıklık oluşmaz. Bu sektörlerde düzenli randevu yapısı hem çalışan verimliliğini hem de müşteri memnuniyetini ciddi şekilde artırır.
Modern Rezervasyon Yazılımlarının Sahip Olması Gereken Özellikler
Yeni nesil rezervasyon yazılımlarının güçlü bir takvim sistemi sunması gerekir. Günlük, haftalık ve aylık görünüm seçenekleri, sürükle bırak yönetimi ve hızlı düzenleme özellikleri kullanım kolaylığı sağlar.
Mobil uyumluluk günümüz şartlarında zorunlu hale gelmiştir çünkü kullanıcıların büyük kısmı randevularını cep telefonu ile oluşturur. Online ödeme alma, kapora talep etme veya faturalama gibi özellikler işletmenin finansal yapısını da iyileştirir.
Bu sistemler aynı zamanda çeşitli entegrasyonlarla çok daha güçlü hale gelir. CRM modülleri, ödeme altyapıları, SMS servisleri ve muhasebe yazılımları ile uyumlu çalışan bir sistem tüm süreci tek panelde yönetebilme avantajı sunar. Kullanıcı yönetimi de bu yazılımların önemli bir parçasıdır. Personel, yönetici ve müşteri gibi farklı kullanıcı rollerine uygun yetki tanımlamaları yapılmalıdır. Bu yapı hem güvenliği artırır hem de iş disiplinini düzenler.
Müşteri Sadakati Oluşturan Dijital Stratejilerin Önemi
Müşteri sadakati işletmeler için uzun vadeli gelir kaynağıdır. Dijital rezervasyon sistemleri bu sadakati oluşturmada önemli bir araçtır. Sadakat programları, puan sistemleri, özel indirimler ve kişiye özel mesajlar müşterilerin işletmeye bağlılığını artırır. Hizmet sonrası gönderilen otomatik geri bildirim formları müşterinin memnuniyet düzeyini ölçmek için oldukça değerlidir.
Bu sayede işletme eksik yönlerini görebilir ve hizmet kalitesini geliştirebilir. İyi yönetilen bir müşteri geri bildirim sistemi işletmenin sürekli gelişimine katkı
sağlar. Kişiye özel öneriler sunmak müşteri ilişkilerini güçlendiren başka bir yöntemdir.
Müşterinin geçmişi analiz edilerek bir sonraki ziyaret için uygun hizmet önerilebilir. Bu strateji hem işletmenin gelirini artırır hem de müşterinin kendisini değerli hissetmesini sağlar.
Gelecekte Rezervasyon Sistemlerinin Evrimi
Gelecekte randevu sistemlerinin yapay zekâ ile daha güçlü bir yapıya kavuşması beklenmektedir. Yapay zekâ destekli öneriler müşteriye en uygun saati sunabilir, yoğunluk analizleri yapabilir ve otomatik programlama gerçekleştirebilir.
Chatbot tabanlı rezervasyon sistemleri müşterilere günün her anında hizmet alma imkânı sağlayacaktır. Rezervasyon yazılımları zamanla sadece randevu almak için değil, geniş kapsamlı işletme yönetim platformları haline dönüşecektir.
Stok yönetimi, finansal raporlama, çalışan performansı, müşteri segmentasyonu gibi birçok fonksiyon tek bir sistem üzerinden yönetilebilir hale gelecektir. İşletmeler bu gelişmelere ayak uydurarak rekabet avantajı elde edebilir ve hizmet kalitesini sürekli yükseltebilir.
- 1
- 2